大模型时代,AI芯片迎来了真正商业化的机会。作者 | 季宇本文来自行云集成电路创始人季宇,更被大家熟知的江湖绰号——mackler,本文是mackler最新演讲,非常精彩。以下是演讲全文:关于大模型,我们听到的最多的就是Scaling。OpenAI通过多年对Scaling的坚持和激进投入,把模型一步步有效推进到千亿万亿规模,实际上证明了AGI这个非常非常难的问题可以通过Scaling这种路径清晰也简单地多的方式去不断逼近。同时OpenAI也把Scale作为他们组织的核心价值观之一来不断逼近AGI。今天不光模型尺寸在Scale,上下文长度也在剧烈地Scale。这种方法论虽然相比AGI这么宏大的目标而言已经足够简化了,但这背后是同等急剧上升的资源投入,单纯的Scale并不是一个经济性的方案。所以我们看到Sam Altman提到7万亿美元的疯狂计划,大家也经常讨论大模型商业落地的巨大成本。大模型的商业落地相比互联网目前有一个非常巨大的区别,就是边际成本仍然非常高。过去的互联网业务,增加一个用户对互联网厂商的基础设施而言,增加的成本几乎是可以忽略不记的。但今天大模型每增加一个用户,对基础设施增加的成本是肉眼可见的增加的,目前一个月几十美元的订阅费用都不足以抵消背后高昂的成本。而且今天的大模型要大规模商业化,在模型质量、上下文长度等方面还有进一步诉求,实际上还有可能需要进一步增加这个边际成本。今天一个日活千万的通用大模型需要一年超过100亿的收入才能支撑其背后的数据中心成本,未来如果我们希望大模型产业真正像今天的互联网产业一样服务上亿人,模型的质量可能也需要进一步上一个台阶,成本会成为很严重的问题。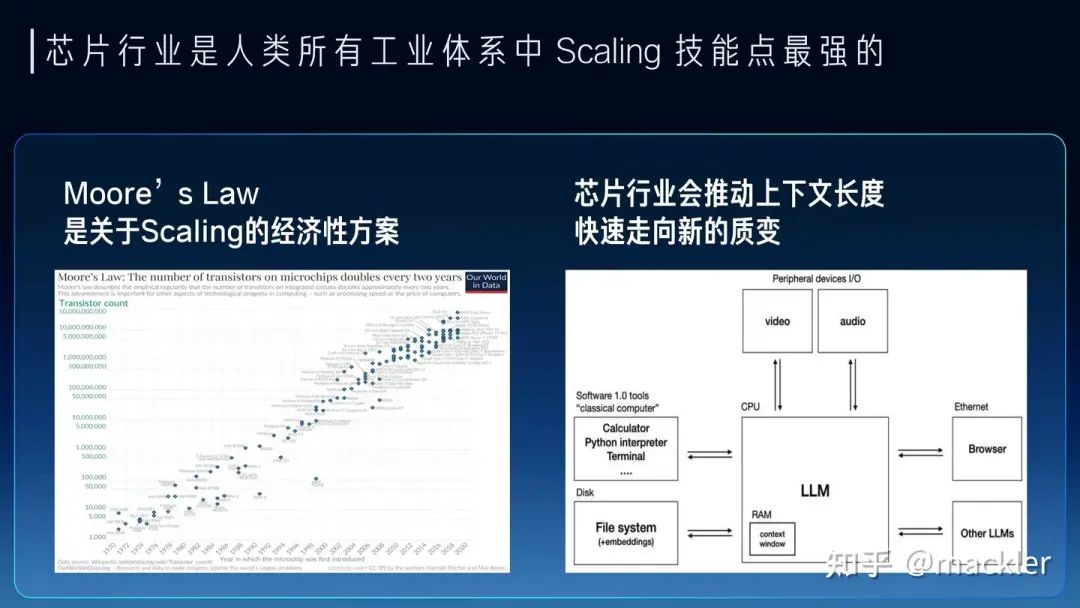 但对于芯片行业而言,只要适当拉长时间尺度,这些都不会是问题。芯片行业是人类所有工业体系中Scaling技能点最强的。过去大半个世纪,半导体行业一直践行的摩尔定律就是一个关于Scaling的经济性方案。其实NVIDIA的老黄评论Sam的7万亿美元计划时也提到,芯片本身也会持续演进来不断降低大模型Scaling所需的资源。7万亿会在几年内逐渐变成7千亿、7百亿,逐渐变成一个不是那么夸张的数字。今天很多人讲大模型的上下文窗口就是新的内存,今天看起来非常宝贵的几K到几M的大模型上下文窗口长度,我们精打细算把重要的信息,各种prompt填入到这有限的上下文窗口里,有点像上个世纪的各种经典小游戏,用很多不可思议的方式在KB级别的内存实现今天看起来已经非常复杂的游戏。但在不远的未来,芯片行业就可以把上下文窗口逐渐变得和今天的内存一样非常便宜,随便一个hello world就直接吃掉MB级别的内存,随便一个应用就GB级别的内存占用。未来我们也一样可以随随便便把一个领域的全部知识装进上下文里,让大模型成为绝对意义上的领域专家,也可以让大模型拥有远超人类一辈子能接受的全部上下文,从而引发大模型走向新的质变。
但对于芯片行业而言,只要适当拉长时间尺度,这些都不会是问题。芯片行业是人类所有工业体系中Scaling技能点最强的。过去大半个世纪,半导体行业一直践行的摩尔定律就是一个关于Scaling的经济性方案。其实NVIDIA的老黄评论Sam的7万亿美元计划时也提到,芯片本身也会持续演进来不断降低大模型Scaling所需的资源。7万亿会在几年内逐渐变成7千亿、7百亿,逐渐变成一个不是那么夸张的数字。今天很多人讲大模型的上下文窗口就是新的内存,今天看起来非常宝贵的几K到几M的大模型上下文窗口长度,我们精打细算把重要的信息,各种prompt填入到这有限的上下文窗口里,有点像上个世纪的各种经典小游戏,用很多不可思议的方式在KB级别的内存实现今天看起来已经非常复杂的游戏。但在不远的未来,芯片行业就可以把上下文窗口逐渐变得和今天的内存一样非常便宜,随便一个hello world就直接吃掉MB级别的内存,随便一个应用就GB级别的内存占用。未来我们也一样可以随随便便把一个领域的全部知识装进上下文里,让大模型成为绝对意义上的领域专家,也可以让大模型拥有远超人类一辈子能接受的全部上下文,从而引发大模型走向新的质变。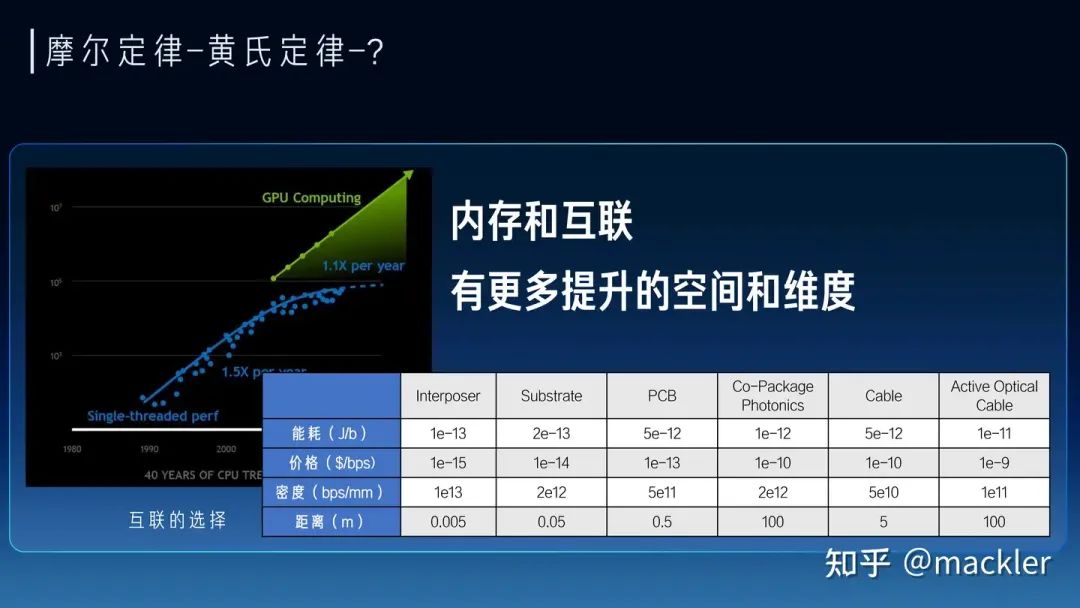 最近几年其实说摩尔定律放缓的观点很多,这也是实际情况,先进工艺的研发投入资金也在指数级飙升,使得维持摩尔定律逐渐变得失去经济性。但芯片行业的Scaling不只是晶体管的微缩推动的,NVidia的GPU过去十年靠架构继续推动放缓的摩尔定律持续保持非常高的增速,算力成本降低了一千倍。而今天大模型进一步打开了更多芯片的演进空间,今天大模型对芯片的需求从算力转向了内存和互联,内存系统和互联的Scale空间更大,除了半导体工艺的演进外,封装工艺的发展、硅光都对内存和互联的设计打开了巨大的空间。大模型今天也早已经全面走向分布式,今天不仅仅是单颗芯片的设计,也进一步扩展到服务器、机柜、网络层面,这些层面都有比原来有大得多的设计空间,未来芯片的增速不仅不会放缓,反而会比今天更快。
最近几年其实说摩尔定律放缓的观点很多,这也是实际情况,先进工艺的研发投入资金也在指数级飙升,使得维持摩尔定律逐渐变得失去经济性。但芯片行业的Scaling不只是晶体管的微缩推动的,NVidia的GPU过去十年靠架构继续推动放缓的摩尔定律持续保持非常高的增速,算力成本降低了一千倍。而今天大模型进一步打开了更多芯片的演进空间,今天大模型对芯片的需求从算力转向了内存和互联,内存系统和互联的Scale空间更大,除了半导体工艺的演进外,封装工艺的发展、硅光都对内存和互联的设计打开了巨大的空间。大模型今天也早已经全面走向分布式,今天不仅仅是单颗芯片的设计,也进一步扩展到服务器、机柜、网络层面,这些层面都有比原来有大得多的设计空间,未来芯片的增速不仅不会放缓,反而会比今天更快。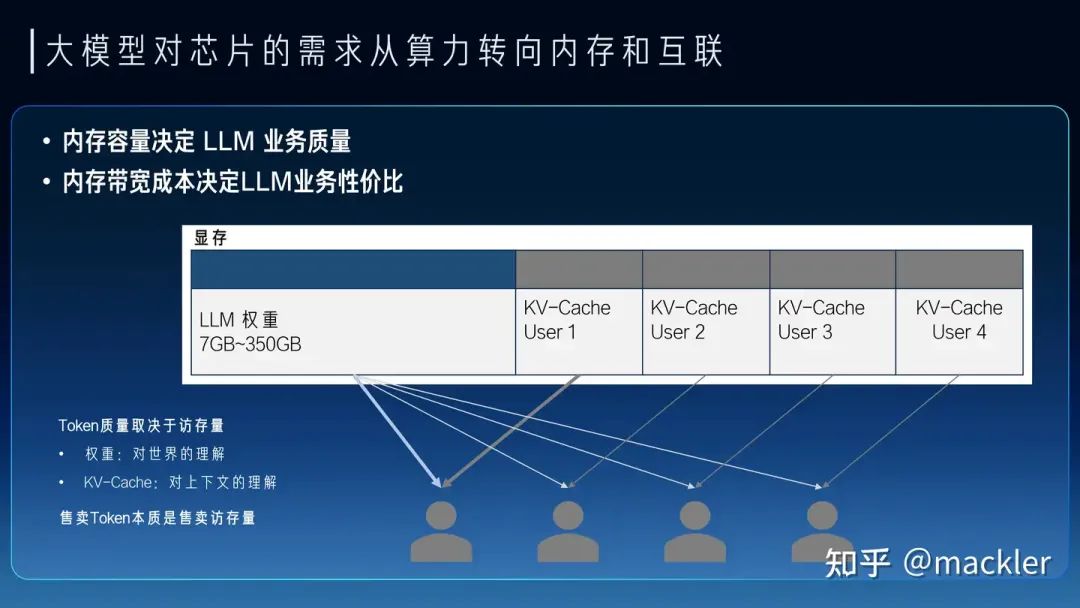 从大模型未来大规模商业化来看,大模型对芯片的主要需求实际上已经转向内存和互联,因为我们需要足够多的高带宽内存通过互联系统连接起来形成一个巨大的高带宽内存来支撑大模型的服务。今天我们经常讨论的售卖Token的价格,实际上Token和Token是不一样的,一个7B模型的Token和千亿万亿模型的Token肯定不等价,一个4K上下文的Token和一个2M上下文的Token也不等价。Token的质量实际上和模型规模以及上下文窗口都是强相关的。模型权重是模型在训练时候对整个数据集的压缩和泛化,是对世界和常识的理解,而上下文对应的KV-Cache是对上下文的理解。而权重和KV-Cache其实也是大模型对内存最主要的需求,这部分的访存速度也决定了Token生成的速度。我们可以把Token的业务质量和这个Token对应的权重以及KV-Cache的总访存量直接挂钩。高质量的Token生成过程中需要更大的访存量,低质量的Token生成过程中需要的访存量也相应更小。而售卖Token对硬件系统而言实际上是售卖内存系统的访存带宽。一个容量足够大的内存系统才能提供足够高质量的Token服务,一个内存带宽性价比足够高的系统才能带来更好的服务成本。物理世界中的内存介质选择往往要带宽就没有容量、要容量就没有带宽。当然这也没办法,如果存在一种内存介质容量和带宽都比另一种都要低,也就被淘汰了,容量和带宽总得占一个才会被筛选出来。所以今天继要容量大又要带宽性价比高,往往需要通过足够有性价比的互联系统将大量高带宽内存连到一起,这里面是存在非常大的设计空间的。这也是中国AI芯片行业真正实现商业化的一次巨大机会,过去十年大家都是在卷算力,算力的竞争往往不只是峰值算力指标的竞争,算力和编程模型、软件都有很强的耦合性,算力指标对先进工艺也有很强的依赖性。这两点实际上造成了过去十年大量AI芯片在产品定义和供应链安全方面都遭遇了巨大的困难。大模型今天把芯片产品的竞争力拉到了内存和互联维度,这些维度相比算力都标准化得多,对解决产品定义问题提供了新的可能性,标准化的维度更贴近指标竞争,就像今天大家买网卡或者交换机时候只关注指标而不关注是哪家的产品,这就是标准化竞争的好处。今天AI芯片可能介于网卡交换机这种纯标准化的竞争和过去那种纯算力这种非标竞争之间,相比过去是存在更多空间来解决产品定义的问题。内存和互联对先进工艺的依赖度相比算力也更少,而且扩大到机柜甚至集群层面,有更多竞争的可能性,今天在封装、互联层面有更多发挥空间,也降低了对先进制程的依赖,在供应链上也存在更多的选择。
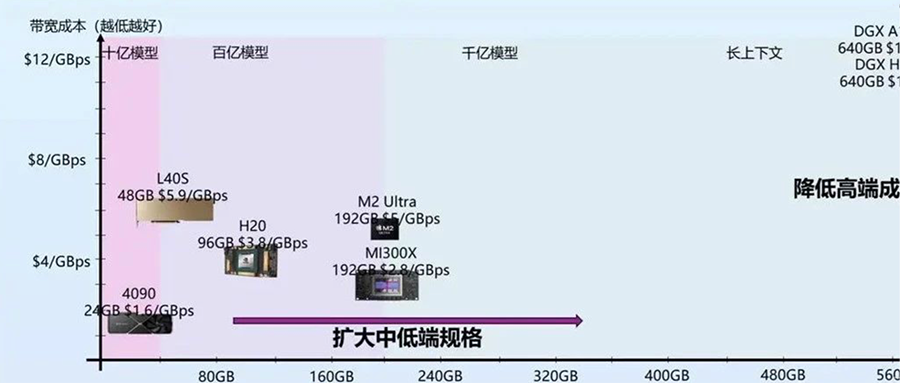
从大模型未来大规模商业化来看,大模型对芯片的主要需求实际上已经转向内存和互联,因为我们需要足够多的高带宽内存通过互联系统连接起来形成一个巨大的高带宽内存来支撑大模型的服务。今天我们经常讨论的售卖Token的价格,实际上Token和Token是不一样的,一个7B模型的Token和千亿万亿模型的Token肯定不等价,一个4K上下文的Token和一个2M上下文的Token也不等价。Token的质量实际上和模型规模以及上下文窗口都是强相关的。模型权重是模型在训练时候对整个数据集的压缩和泛化,是对世界和常识的理解,而上下文对应的KV-Cache是对上下文的理解。而权重和KV-Cache其实也是大模型对内存最主要的需求,这部分的访存速度也决定了Token生成的速度。我们可以把Token的业务质量和这个Token对应的权重以及KV-Cache的总访存量直接挂钩。高质量的Token生成过程中需要更大的访存量,低质量的Token生成过程中需要的访存量也相应更小。而售卖Token对硬件系统而言实际上是售卖内存系统的访存带宽。一个容量足够大的内存系统才能提供足够高质量的Token服务,一个内存带宽性价比足够高的系统才能带来更好的服务成本。物理世界中的内存介质选择往往要带宽就没有容量、要容量就没有带宽。当然这也没办法,如果存在一种内存介质容量和带宽都比另一种都要低,也就被淘汰了,容量和带宽总得占一个才会被筛选出来。所以今天继要容量大又要带宽性价比高,往往需要通过足够有性价比的互联系统将大量高带宽内存连到一起,这里面是存在非常大的设计空间的。这也是中国AI芯片行业真正实现商业化的一次巨大机会,过去十年大家都是在卷算力,算力的竞争往往不只是峰值算力指标的竞争,算力和编程模型、软件都有很强的耦合性,算力指标对先进工艺也有很强的依赖性。这两点实际上造成了过去十年大量AI芯片在产品定义和供应链安全方面都遭遇了巨大的困难。大模型今天把芯片产品的竞争力拉到了内存和互联维度,这些维度相比算力都标准化得多,对解决产品定义问题提供了新的可能性,标准化的维度更贴近指标竞争,就像今天大家买网卡或者交换机时候只关注指标而不关注是哪家的产品,这就是标准化竞争的好处。今天AI芯片可能介于网卡交换机这种纯标准化的竞争和过去那种纯算力这种非标竞争之间,相比过去是存在更多空间来解决产品定义的问题。内存和互联对先进工艺的依赖度相比算力也更少,而且扩大到机柜甚至集群层面,有更多竞争的可能性,今天在封装、互联层面有更多发挥空间,也降低了对先进制程的依赖,在供应链上也存在更多的选择。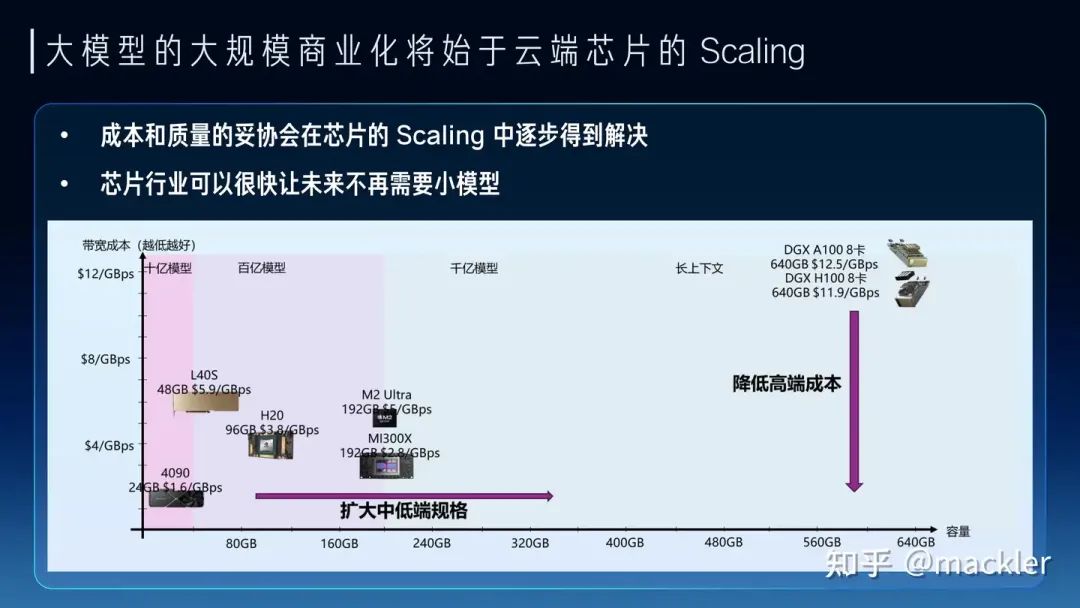 我们如果看当下和未来两三年,其实大模型的商业探索也是在成本和Token质量上相互妥协,也逐渐分化成了两派。一派是质量优先,用高端系统打造高质量的通用大模型,寻找超级应用来覆盖高昂的成本。另一派是成本优先,用足够便宜的硬件上,提供基本够用的Token质量,寻找垂直场景的落地。从芯片未来两三年的短期Scaling来看,也会从两个路径来解决这两派在成本和质量上的纠结。一种是高端系统的成本的大幅度下降,显著降低超级应用需要承担的成本,另一种是低端设备的规格大幅提升,显著提升低成本设备下可以支持的Token质量。今天很多人讲7B模型已经够用了,或者努力让7B或者更小的模型变得够用,其实也是一种无奈,如果能在同样的成本下买到规格大得多的芯片,跑一个百亿千亿模型,支持超长上下文,商业化的空间会比今天大得多,就像曾经的显卡和游戏行业一样,当足够便宜的显卡已经可以流程跑4k画质的时候,谁还会觉得1080p的画质也够用了呢?两三年后,随着芯片行业的发展,不会再有人需要小模型,大模型长文本的高质量Token会变得足够便宜。
我们如果看当下和未来两三年,其实大模型的商业探索也是在成本和Token质量上相互妥协,也逐渐分化成了两派。一派是质量优先,用高端系统打造高质量的通用大模型,寻找超级应用来覆盖高昂的成本。另一派是成本优先,用足够便宜的硬件上,提供基本够用的Token质量,寻找垂直场景的落地。从芯片未来两三年的短期Scaling来看,也会从两个路径来解决这两派在成本和质量上的纠结。一种是高端系统的成本的大幅度下降,显著降低超级应用需要承担的成本,另一种是低端设备的规格大幅提升,显著提升低成本设备下可以支持的Token质量。今天很多人讲7B模型已经够用了,或者努力让7B或者更小的模型变得够用,其实也是一种无奈,如果能在同样的成本下买到规格大得多的芯片,跑一个百亿千亿模型,支持超长上下文,商业化的空间会比今天大得多,就像曾经的显卡和游戏行业一样,当足够便宜的显卡已经可以流程跑4k画质的时候,谁还会觉得1080p的画质也够用了呢?两三年后,随着芯片行业的发展,不会再有人需要小模型,大模型长文本的高质量Token会变得足够便宜。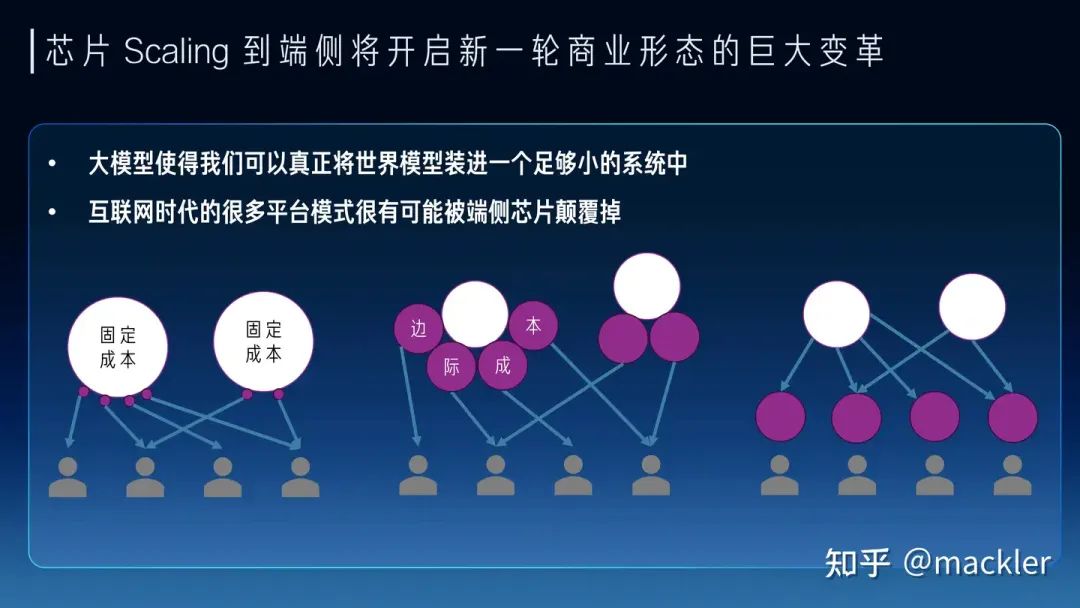 往更长远看,大模型的成本模型对于商业形态都会产生巨大的变革。很多传统互联网业务具有巨大的固定成本,而边际成本非常低,一个集中式的云往往就是最经济的商业形态。今天大模型实际上把信息高度压缩到一个足够小的系统中,甚至是单个用户在未来可能承受的。同时,今天大模型服务的边际成本相比固定成本占比已经非常高,短期内仍然在云端更多是因为边际成本对于用户来讲还是太高了,并且商业模式也还未大规模爆发,用户也不会愿意为一个尚未大规模商业化的需求承担这部分边际成本。因此未来两三年内仍然是云端承担大量的边际成本来探索商业化的可能性,芯片行业帮助降低成本加速商业化。但随着大模型大规模商业化爆发,这种成本模型实际上会造成巨大的浪费。试想一下以后我们常用的几十种不同的应用都独自提供大模型服务,这些边际成本对于所有厂商都是巨大的,而羊毛出在羊身上,最终还是会转嫁到消费者身上,就像今天需要付费订阅各种大模型厂商。随着芯片行业进一步降低成本,大模型落到端侧会变成总体更加经济的成本模型。就像今天的游戏市场,游戏画质的成本是游戏玩家自己买的显卡来承担,游戏玩家也无需为想玩的不同游戏单独为画质付费,游戏厂商也无需承担这部分成本。大模型也是类似的,未来芯片的Scaling让用户可以在端侧低成本跑极高质量的大模型,无需为不同的云端服务承担独立的大模型订阅费用,大模型的高度智能也能更容易打破不同应用之间的壁垒,还能在端侧更好地协同起来,实现更好的体验。当然这和今天AI PC这一类在端侧跑低成本的小模型还是有本质区别的,还有待于芯片行业的迭代,让大家能在比今天更低的成本下跑起来未来的旗舰模型。我们相信大模型能随着芯片行业的Scaling逐渐低成本走进千行百业,也走进大家的生活。我们也相信在大模型时代,AI芯片迎来了真正商业化的机会,可以把产品定义和供应链的问题解决好,也在更多维度创造出更有竞争力的芯片产品。我们行云也希望在未来努力把这些都变成现实。
往更长远看,大模型的成本模型对于商业形态都会产生巨大的变革。很多传统互联网业务具有巨大的固定成本,而边际成本非常低,一个集中式的云往往就是最经济的商业形态。今天大模型实际上把信息高度压缩到一个足够小的系统中,甚至是单个用户在未来可能承受的。同时,今天大模型服务的边际成本相比固定成本占比已经非常高,短期内仍然在云端更多是因为边际成本对于用户来讲还是太高了,并且商业模式也还未大规模爆发,用户也不会愿意为一个尚未大规模商业化的需求承担这部分边际成本。因此未来两三年内仍然是云端承担大量的边际成本来探索商业化的可能性,芯片行业帮助降低成本加速商业化。但随着大模型大规模商业化爆发,这种成本模型实际上会造成巨大的浪费。试想一下以后我们常用的几十种不同的应用都独自提供大模型服务,这些边际成本对于所有厂商都是巨大的,而羊毛出在羊身上,最终还是会转嫁到消费者身上,就像今天需要付费订阅各种大模型厂商。随着芯片行业进一步降低成本,大模型落到端侧会变成总体更加经济的成本模型。就像今天的游戏市场,游戏画质的成本是游戏玩家自己买的显卡来承担,游戏玩家也无需为想玩的不同游戏单独为画质付费,游戏厂商也无需承担这部分成本。大模型也是类似的,未来芯片的Scaling让用户可以在端侧低成本跑极高质量的大模型,无需为不同的云端服务承担独立的大模型订阅费用,大模型的高度智能也能更容易打破不同应用之间的壁垒,还能在端侧更好地协同起来,实现更好的体验。当然这和今天AI PC这一类在端侧跑低成本的小模型还是有本质区别的,还有待于芯片行业的迭代,让大家能在比今天更低的成本下跑起来未来的旗舰模型。我们相信大模型能随着芯片行业的Scaling逐渐低成本走进千行百业,也走进大家的生活。我们也相信在大模型时代,AI芯片迎来了真正商业化的机会,可以把产品定义和供应链的问题解决好,也在更多维度创造出更有竞争力的芯片产品。我们行云也希望在未来努力把这些都变成现实。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


