本文授权转载自公众号“半导体行业观察”,ID:icbank,作者:L晨光。
近年来,在AI高算力需求推动下,HBM正在大放异彩。
尤其是进入2023年后,以ChatGPT为代表的生成式AI市场的疯狂扩张,在让AI服务器需求迅速增加的同时,也带动了HBM高阶存储产品的销售上扬。
TrendForce数据显示,2023年全球搭载HBM总容量将达2.9亿GB,同比增长近60%,预计2024年还将再增长30%。SK海力士预测,HBM市场到2027年将出现82%的复合年增长率。
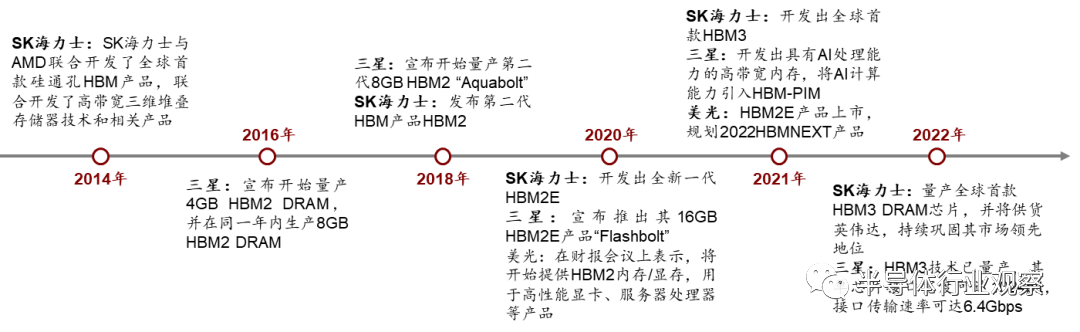
在此发展势头下,作为AI芯片的主流解决方案,HBM受到了存储巨头的高度重视。自2014年SK海力士首次成功研发HBM以来,三星、美光等存储巨头也纷纷入局,展开了HBM的升级竞赛,目前HBM已从第一代HBM升级至第四代HBM3,产品带宽和最高数据传输速率记录被不断刷新。下一代HBM3E超带宽解决方案也已在样品测试阶段,HBM4也被提上议程。
 ▲HBM发展历程
▲HBM发展历程
借助AI东风,HBM需求水涨船高,三大原厂纷纷推动HBM新代际产品开发与产线扩张。与此同时,台积电也宣布将CoWoS产能扩大两倍,以期更好地支撑水涨船高的HBM需求。
近日,英伟达H200的推出有望再次掀起HBM布局浪潮,未来在AI大模型日趋复杂化的趋势下,随着存储巨头的持续发力,产业链上下游企业也将紧密部署,HBM的影响力将逐步扩大并带来全新机遇。
关于HBM技术的未来发展路线,在我们之前的文章《HBM 4,要来了》有比较详细的介绍;以及在《HBM的崛起》、《存储巨头竞逐HBM》文章中,更是详细介绍了HBM的前世今生,以及存储巨头围绕HBM的产业布局和规划。感兴趣的读者可以点击链接自行跳转查阅。
本文,将围绕HBM发展过程中的一个细分环节——硅中介层(Si-Interposer),来详述其价值、瓶颈以及未来的技术走向。
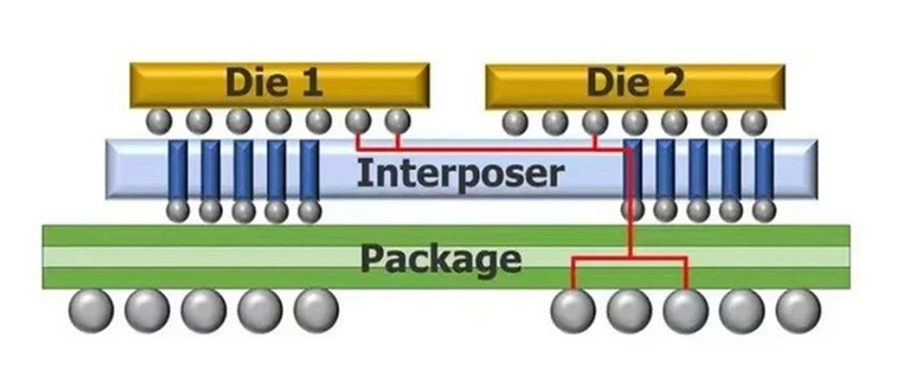
谈到硅中介层,我们需要先来了解一下HBM的结构。
与传统DDR存储器不同,HBM使用硅通孔技术(TSV)和微凸块(ubump)垂直堆叠多个DRAM芯片,并通过封装基板内的硅中介层与GPU、CPU或ASIC直接相连,从而具备高带宽、高容量、低延时与低功耗等优势,相同功耗下其带宽是DDR5的三倍以上。
因此,HBM突破了内存瓶颈,成为当前AI GPU存储单元的理想方案和关键部件。
 ▲HBM架构示意图
▲HBM架构示意图
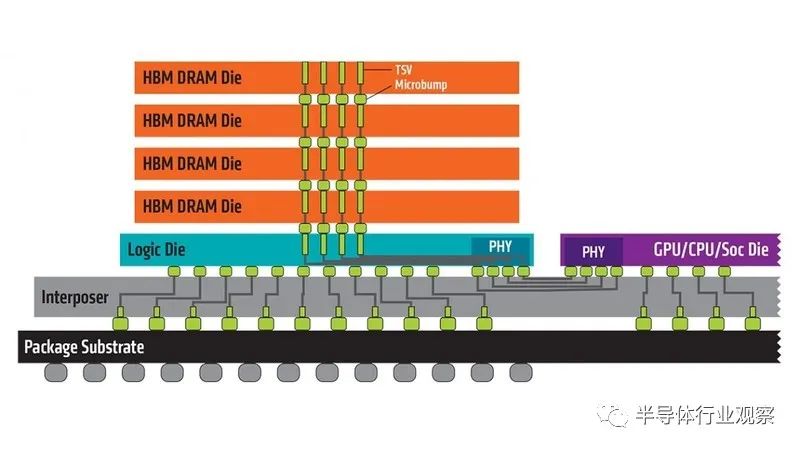
HBM是一种标准化的堆栈储存技术,可为堆栈内部,以及内存与逻辑组件之间的数据提供高带宽信道。HBM封装将内存裸晶堆栈起来,并透过TSV将它们连接在一起,从而创建更多的I/O和带宽。
从上图可以看到,这个硅中介层可以理解为一块精密的电路芯片,里面布置了密集的电信号传输通道,用于帮助芯片、封装基板进行电性能互连,实现芯片与芯片,芯片与封装基板之间的信息交换,可以用于提高芯片的性能和带宽,以及使芯片更加紧凑,从而减少了信号传输的延迟和功耗。
总体来看,硅中介层是一种经过验证的技术,具有较高的细间距I/O密度和TSV形成能力,在2.5D IC芯片封装中扮演着关键角色。
硅中介层有两种技术路线,代表分别是台积电的CoWoS和英特尔的EMIB。
台积电CoWoS-S通过硅中介层承载处理器和HBM,处理器和若干HBM的投影面积决定了硅中介层的大小,而中介层的面积受限于光刻掩膜尺寸,会限制HBM的使用数量。
这就成为了早期HBM应用的瓶颈——需要HBM的往往是高性能的大芯片,而大芯片的规模本身就已经逼近了掩膜尺寸极限,给HBM留下的面积非常有限。对此,台积电相继攻克了多重困难突破了中介层尺寸的限制,单芯片内部逐渐可封装4颗、6颗,甚至12颗HBM。
硅中介层的面积如此发展,在解决尺寸限制的同时,也带来了新的挑战,即成本越来越高。以8GB HBM2为例,其成本约175美元,其中硅中介层成本约25美元,而同时期的8GB GDDR5仅需52美元,在没有考虑封测的情况下,HBM成本已经是GDDR的三倍左右。
尤其是随着HBM的演进,中介层面积越来越大,要包含所有的Die,大大增加成本。此外,中介层是有半导体工艺制作,成本不低,且很难做很大面积。
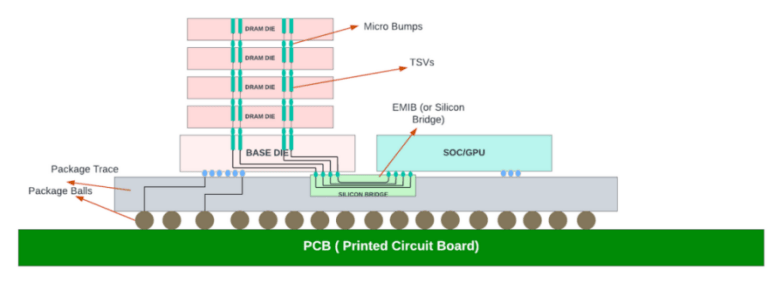
为了降低中介层的成本和尺寸,英特尔发明了EMIB,将die-die的互连用“硅桥(Si Bridge)”实现,且硅桥嵌入在基板内部,die-substarte的连接通过传统方法实现。这种做法可以大大降低硅中介层的面积,减少成本,减轻多die封装的限制。
 ▲英特尔EMIB架构图
▲英特尔EMIB架构图
值得注意的是,EMIB通过非常小的凸点间距提供高互连密度,从而允许芯片之间具有更高的带宽,并且由于走线长度较短,因此比使用有机基板具有更低的功耗。它类似于微型硅中介层,仅覆盖小芯片之间需要连接的区域。
但是,尽管EMIB充分利用了硅中介层和有机载板的技术特点和电气特性,但也存在组装成本高的缺点,因为需要在有机载板中镶嵌,增加了工艺复杂度,限制了载板的选择。
因此,为了进一步降低成本,行业厂商开始研究弃用硅中介层的技术和方法。
1、SK海力士:直接在处理器上堆叠HBM4据报道,SK海力士开始招聘CPU和GPU等逻辑半导体设计人员,希望直接在处理器上堆叠HBM4,这不仅将改变逻辑芯片和内存的典型互连方式,还将改变其制造方式。
目前,HBM堆栈集成了8个、12个或16个存储器件,以及一个像集线器一样的逻辑层。HBM堆栈被放置在CPU或GPU旁的中间件上,并通过1024位接口与处理器相连。SK海力士的目标是将HBM4堆栈直接放在处理器上,完全省去中介层。
据悉,SK海力士正在与包括英伟达在内的几家公司讨论其HBM4集成设计方法。SK海力士和英伟达很有可能从一开始就联合设计芯片,并在台积电生产,台积电还将使用晶圆键合技术把SK海力士的HBM4安装到逻辑芯片上。为了使内存和逻辑半导体在同一芯片上作为一个整体工作,联合设计是不可避免的。
台积电目前也有像SoIC等更高级的3D封装工艺,确实可以将更好的将显存堆叠到芯片之上,就像AMD的3D V-Cache处理器就是用到了这种工艺,不过该处理器最大的问题就是发热,还有良率以及成本等因素,目前还不太适用于HBM显存。
据业内人士表示,直接连接存储器和逻辑芯片在经济上是可行的。不过,虽然将HBM4堆栈直接放在逻辑芯片上可以在一定程度上简化芯片设计并降低成本,但这也带来了另一个挑战——散热。
散热本身就是HBM长期存在的挑战之一,HBM的2.5D封装结构会集聚热量,而靠近CPU和GPU的布局又会进一步增加热量。以Nvidia的H100处理器为例,其消耗数百瓦的功率,并耗散数百瓦的热能,且HBM内存也相当耗电。
目前来看,如果发热问题能够得到解决,HBM的“游戏规则”可能会发生变化,存储器和逻辑半导体之间的连接可能会变得像一体机一样运行,而无需中间件。
2、三星:将HBM存储与芯片封装解耦三星方面也认为,随着封装变得越来越大,带来了装配和可靠性等多方面的挑战。为此,三星通过提供一个在logic die上堆叠DRAM die的方法,将功耗效率提升了40%,并将延迟降低了10%。
在另一种方案中,三星将Cash DRAM堆叠在logic die上,使得功耗效率提升了60%,延迟则降低了50%。在三星看来,这是一个更好的、面向未来解决方案。

展望未来,三星方面进一步指出,光互连将发挥重要作用。
在使用光学I/O后,将获得非常高的带宽密度;与此同时,这种解决方案还能带来非常低的功耗。在三星看来,光学I/O将逻辑封装和存储封装连接到一起。
同时,该技术还能将HBM存储与芯片封装完全解耦,将HBM模组从芯片本体分离出来,并通过光学技术与逻辑处理单元相连。这样就不必处理中介层带来的芯片封装复杂性,且这种方法简化了HBM和逻辑单元的芯片制造与封装成本,并且避免了复杂的数字到光学信号内部转换。
随着全球存储巨头的深度介入,上述挑战或将得到解决,HBM市场的激战也会愈演愈烈。
除了存储原厂之外,台积电等厂商也正在通过研发不同类型的中介层,或是采用不同的材料来实现成本节降。
以台积电为例,台积电正在不断尝试降低下一代HBM的成本,宣布拥有多种不同类型的中介层:除了硅中介层外,还有RDL中介层,以及其他试图摆脱中介层的技术探索。
比如CoWoS-R、CoWoS-L等,前者将硅中介层换做有机RDL,能够降低成本,不过劣势是牺牲了I/O密度;后者是台积电专门针对AI训练芯片设计的,结合了台积电CoWoS-S和信息技术的优点,预计晚些时候才能应用。
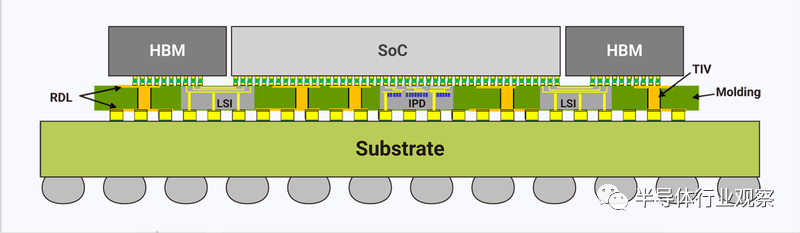 ▲图源:TSMC官网
▲图源:TSMC官网
此外,集成扇出封装技术(INFO)也正在考虑集成HBM,作为硅中介层的经济替代方案等等...。Cadence IP团队产品营销总监Marc Greenberg表示,如果行业能够聚集在一起并决定一个适用于标准封装的内存标准,那么就有可能提供与HBM类似的带宽,且成本要低得多。
可见,弃用硅中介层或进一步降低成本正在成为HBM未来新的技术创新路线。成本因素之外,HBM干掉硅中介层还可以减小传输路径、提升传输速率,体积也会更加小。
在HBM弃用硅中介层的迹象之外,Chiplet也正在进行此方面的探索(其实某种程度上,HBM就是Chiplet的一种类型)。
迄今为止,业界领先的Chiplet互连需要先进封装和昂贵的硅中介层。而Eliyan公司验证了他们在高性能Chiplet互连方面的突破。
笔者在此前文章《Chiplet,怎么连?》中对此有过详细介绍。
Eliyan凭借其Nulink技术,可以为die-to-die互联在各种封装衬底上提供功耗、性能和成本的优势方案。因为这种PHY接口可以让不同的裸片直接在有机衬底上实现高速互联,而不必采用CoWoS、EMIB或硅中介层等昂贵的先进封装方式,在降低成本的同时加速产品制造周期。

从上图可看到,左边是当今常见的使用硅中介层的Chiplet互连方法;右边是Eliyan的NuLink技术,可以以卓越的带宽实现小芯片互连,而无需硅中介层。
可见,NuLink通过简化系统设计降低了系统成本。更重要的是,Eliyan可以增加芯片之间的距离,对于生成式AI,NuLink为每个ASIC提供更多的HBM内存,从而提高了配备HBM的GPU和ASIC的内存密集型应用程序的性能。
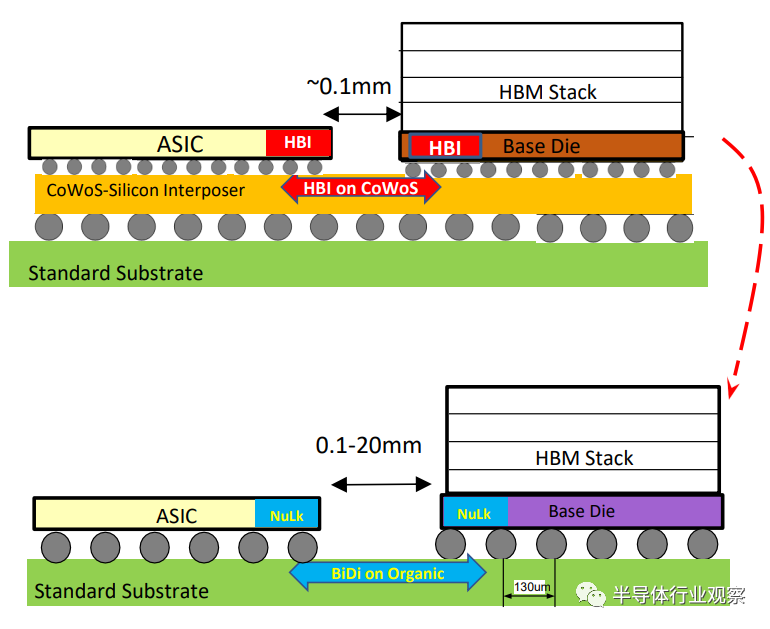 ▲采用硅中介层的传统Chiplet解决方案与采用有机基板的Eliyan Nulink
▲采用硅中介层的传统Chiplet解决方案与采用有机基板的Eliyan Nulink
Eliyan还展示了其NuLink PHY的第一个工作芯片,该芯片采用5nm标准制造工艺实现,可以让Chiplet与不同工艺的裸片实现混搭,不需要硅中介层等先进封装技术。
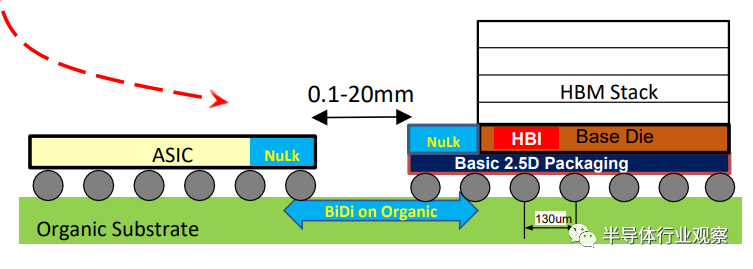 ▲NuGear消除了对大型硅中介层的需求
▲NuGear消除了对大型硅中介层的需求Eliyan指出:“如今业内的一大需求是能够获得足够大的中介层,这样就可以构建越来越大的GPU或TPU,并带有大内存。”
这还是在抛开成本因素的考量下,而Nulink有机基板的尺寸可以达到硅中介层的三四倍,同时提供相同或更好的功率效率和带宽。这导致成本更低、制造速度更快,每个封装的计算能力更强。
与此同时,NuLink还为HBM DRAM提供卓越的散热性能,消除了HBM-ASIC之间的热串扰,允许ASIC时钟速度提高20%,以及更简单/低成本的冷却。
测试和产量是另一个优势。传统硅中介层需要使用微凸块将小芯片连接到中介层引线,微凸块限制了对晶圆进行全面测试的能力,使良率面临风险。
对此,Nulink对有机基板的使用通过允许使用具有标准尺寸凸块的小芯片来缓解这个问题,这可以更有效地进行测试。因此,可以将芯片良率从60%提高到90%左右。
总结来看, Eliyan消除了对先进封装的需求,例如Chiplet设计中的硅中介层尺寸有限、成品率低、成本高、难以冷却、供应链有限、测试等所有相关限制和复杂性。NuLink技术能够实现DRAM扩展、节约材料成本、提高产量并缩短芯片上市时间等优势。
Eliyan认为,其Chiplet互连产品可以超越英特尔和台积电等芯片巨头的先进封装技术,或者有望成为英特尔、台积电的最佳选择,从而实现下一波高性能芯片架构。NVIDIA、Intel、AMD和Google等公司可以授权NuLink IP,或从Eliyan购买NuGear小芯片,以消除硅中介层尺寸限制带来的性能瓶颈,使他们能够实现更高性能的AI和HPC SoC。
但任何技术都有两面性,并非提供完全的优势。例如,Eliyan新技术可以把Chiplet从2.5D的封装要求切换到2D上,但必然需要增大线速来换取更低的线密度需求。但速率的增加对于PHY的设计会引入显著的额外延时和能耗。
总的来说,无论是HBM、Chiplet异构集成,还是裸片堆叠,这些先进封装技术正逐步解决传统芯片缩放遇到的难题,同时也为未来的芯片设计提供了更多的灵活性和高效性。
同时随着互连技术的演进,预计将进一步促进HBM或Chilet封装技术的进步,为行业带来更低功耗、更高性能以及更低成本的解决方案。
无论是哪种技术,都各有优劣,也永远面对新的瓶颈和挑战,需要根据实际需求来进行设计和选择。但万变不离其宗,持续提升性能、降低成本,无疑是行业发展永久的“必杀技”。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

