AMD王宏强:700亿参数大模型单个GPU部署,做好AI软件和生态实现“开箱即用”丨GACS 2023
芯东西 | 2023-10-09 08:32:48 阅读:492
 发布文章
发布文章
从云到端五大产品线全面拥抱AI,AI正成为AMD的新大招。编辑 | GACS9月14日-15日,2023全球AI芯片峰会(GACS 2023)在深圳市南山区圆满举行。在首日主题演讲中的AI芯片架构创新专场,AMD人工智能事业部高级总监王宏强分享了主题为《AMD Pervasive Al:从数据中心、边缘、客户端到终端,Al无所不在》的主题演讲。AMD人工智能事业部高级总监王宏强谈道,AMD在单个GPU能做到上千T的浮点算力规模,通过多节点横向扩展,更是能达到每秒百亿亿次浮点计算能力(EFLOPS),并提供额外的超大内存容量及带宽,可实现700亿参数级大模型在单个GPU上的部署,并达到更高的TCO(总拥有成本)。王宏强也特别强调了AMD AI软件的易用性以及强大的开放软件生态的重要性,它是释放这些创新硬件性能的关键。AMD通过统一AI软件实现跨平台AI部署,以开放和模块化的方式构建软件解决方案,从而拥抱更高层次的抽象,并与最重要的生态系统(PyTorch, ONNX, HuggingFace, Open AI Trito, Open XLA等)合作对接推动开箱即用的用户体验。以下为王宏强的演讲实录:尊敬的各位嘉宾,各位同行,下午好!我很荣幸今天有机会参加芯东西举办的AI峰会上,这也是AMD第一次在线下参加芯东西举办的AI峰会。今天我将与大家分享AI无所不在,无限可能的人工智能变革时代。人工智能领域正在快速变化。处理如此大量数据的计算能力对于人工智能的发挥至关重要。
01.从云到端,全产品线看向AI,AMD瞄准1500亿美元AI芯片市场
人工智能(AI)正在快速地变化、快速地发展,特别是随着ChatGPT的推出。所以要处理如此大量的AI计算,我们需要有非常强大的AI处理能力硬件平台和开放的AI软件生态系统。AMD是非常专注于异构计算的一个公司,我们将很大一部分投入放在研发处理AI的平台上,从数据中心,边缘,到端,这种全产品线的AI加速解决平台。同时,我们也非常致力于专注发展开放的AI软件生态系统。在AMD,非常有幸的是我们有很多产品线,我们可以为不同的市场来服务。比如说,在数据中心的云端,我们有强大的EPYC处理器,用我们平常说的最多的一句话是“它是比强者更强的CPU”,从96核到128核的CPU,都已经陆续推出,它们可以用来做通用AI。
同时,我们也有MI GPU,可以用于数据中心的AI推理和训练。我们也有用于工业、医疗、科学、自动驾驶等应用的嵌入式平台。我们的客户群非常地广泛,有数千个嵌入式的客户使用我们这些产品。我们也推出了消费级的带有AI功能的Ryzen AI PC端加速平台。AMD也正是看到这些传统的算法和应用正在被人工智能所替代,特别是AIGC,它让AI变得普遍存在,甚至在各个行业、各个应用中都可以利用它来为我们人类提供一些更加便利、更加丰富的生活,带来更加安全的驾驶,这些都是需要AI技术和平台来作为支撑。AI最终将变得非常普遍,无所不在,人工智能技术将会是在整个产业界、行业一个绝对性的大趋势,引领整个社会的变革。整个AI市场,也是极速地在增长,所以它的机会是无限可能。预计到2027年,在整个AI市场中,芯片市场就将达到1500亿美元,所以这也是各家企业逐鹿的一个战略重地。
02.AI需求多样化对芯片架构提出挑战,AMD推出多样针对性架构创新
随着这些多样化的人工智能应用的发展,越来越明显的是没有一种单一的架构或者产品可以去适应所有应用的需求。因为各种需求不一样,有的是需要很高的计算能力,有的需要很大的内存,有的可能需要一个更低的延时或者是更低的功耗。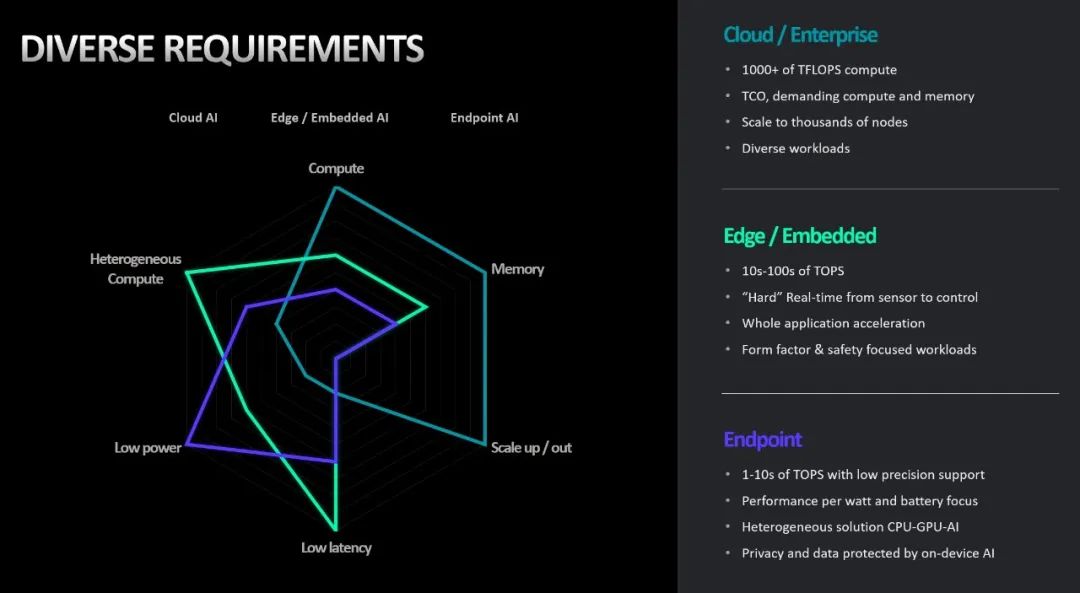
比如在笔记本中,功耗就成为一个非常关键的因素。而在云中,有超高的算力的需求、内存的需求,需要数千万亿次的计算来满足计算负载。比如训练一些大模型,是需要上千个GPU节点才可能完成,这些都是需要我们提供强大的计算,存储的支撑来满足。例如自动驾驶,它对延迟的需求是非常严格的,比如你需要在毫秒级的时间范围里做出一个响应,比如对路况的判断、有没有行人、路标的检测、要做一系列决策来达到自动驾驶的安全性。这些可能需要上百TOPS的算力,同时还要求一个相对比较低的功耗。在端侧,像笔记本电脑这些,对于算力能耗比很关注,电池的消耗是非常关键的一个因素。比如我们在Teams、Zoom上开会,就会利用笔记本电脑端侧的AI功能,让会议系统变得更加智能化。在AMD,我们针对这些不同的需求进行了架构的创新。一方面,我们高性能的旗舰CDNA架构,建立在之前多代GPU的基础上。业界有说道:AMD其实是中国GPU的“黄埔军校”。可见,AMD在GPU上还是有很多技术上的积累和创新的。为行业提供最高性能的AI计算解决方案,并为最大的超级计算机提供支持,以在单个计算上适应最大的人工智能推理工作负载。GPU它提供了一个灵活的编程模型来运行通用workloads,单个计算节点或者GPU来算,我们甚至可以做到数千TOPS的能力。我们也可以横向的扩展,使用多个节点,达到千万亿次浮点运算的能力。另外一方面,我们有XDNA架构,它是基于AI引擎的处理架构,它也是一个并行的阵列数据流处理架构,我们有可以提供一个非常高速的、低延时的实时处理,因为它采用的是数据流的架构来优化。上午有同行分享到Chiplet,XDNA就是AMD产品线里非常重要的一个Chiplet,也是重要的一个计算单元,因为它可以扩展到不同的平台里面。比如在终端,边缘测嵌入式器件里面,可以集成AI引擎的Chiplet。
这些平台是基于Chiplet的架构,所以可以根据算力需求去集成相应数量的AI Engine,达到提供这种可扩展计算的能力。同时,我们可以与CPU、与传统FPGA还有存储器集成在一起,做一个异构计算平台,来满足各种计算的需求。甚至可以在器件里面去集成RDNA架构的独立的显卡iGPU,在一个APU里面。
03.五大产品线多点出击,700亿参数大模型单个GPU部署
我们接下来就看一下基于这些架构的产品示例。AMD的战略,是要为业界、为同行提供最广泛的计算产品的组合,以满足人工智能这种普遍性的、多样性的需求。在这方面,我们也取得了非常大的进展,我们有陆续的推出这些产品。这些(见PPT),都是我们已经推出来的产品。在数据中心,我们有基于CDNA架构的Instinct数据中心GPU,它可以满足AIGC,这些生成式AI的workload的训练或推理。EPYC处理器,有远超于同行的CPU核心数,目前我们可以达到128个核心数,这些都为通用AI提供了强大计算平台。基于Radeon架构的GPU,它可以通过AI技术增强游戏体验变得更好。Versal AI Edge产品系列,主要目标市场是为嵌入式或者边缘侧的应用。对端侧的应用,今年5月份,我们推出了Ryzen AI,这个产品是集成了CPU、XDNA AI Engine的IPU,还有RDNA的iGPU集成在一个异构计算平台里,可以用来满足电脑市场这些AI推理的需求。这个产品已经发货,已经有超过35个PC系列里,集成了Ryzen AI这款产品。接下来我们具体看一下,这些产品如何去满足这些多样化的AI市场需求。AMD的Instinct GPU主要是用在数据中心,它是专为生成式AI而设计的GPU。它将CDNA 3与业界领先的HBM3相结合,采用业界领先的2.5D/3D Chiplet结构构建,它提供高达数千TOPS的计算能力,并提供额外的,超大的内存容量,我们对大模型有优势,因为我们可以直接在内存中运行更大的模型,减少所需的GPU数量显着提高性能,尤其是推理性能。
这个产品可以支持700亿参数的模型在单个GPU上做部署,是因为它有更大的内存容量及带宽。业界其他的GPU不能做到700亿参数的模型在同一个GPU里部署,可能需要两个GPU来实现。请继续关注,我们将在今年晚些时候分享有关该产品的更多信息。我们刚刚讲的是在数据中心这一侧。其实终端AI也在快速发生变化。今年早些时候,我们推出了Ryzen AI系列,这个产品是基于我们XDNA的核心引擎作为基础AI推理及运算,在一个APU封装里面集成了CPU、iGPU。投入到市场以来,其受到业界ISV,OEM的追捧,有35个笔记本电脑已经利用到这个产品来提供AI解决方案。
AMD Ryzen AI的专用AI硬件开启个人电脑新时代,电脑首先会被AI化,Windows12即将发布,将全面基于AI(ChatGPT)技术。据行业专业人士分析:“AI将改变电脑的每一个应用、每一个体验!今天买电脑,推荐买AI电脑!
04.AI不止于硬件,软件开发和生态系统建设是重中之重
我们刚刚讲了很多硬件相关的,与支持这些创新硬件的架构创新一样,我们需要强大的AI软件及生态来使能发挥这些创新硬件们的性能。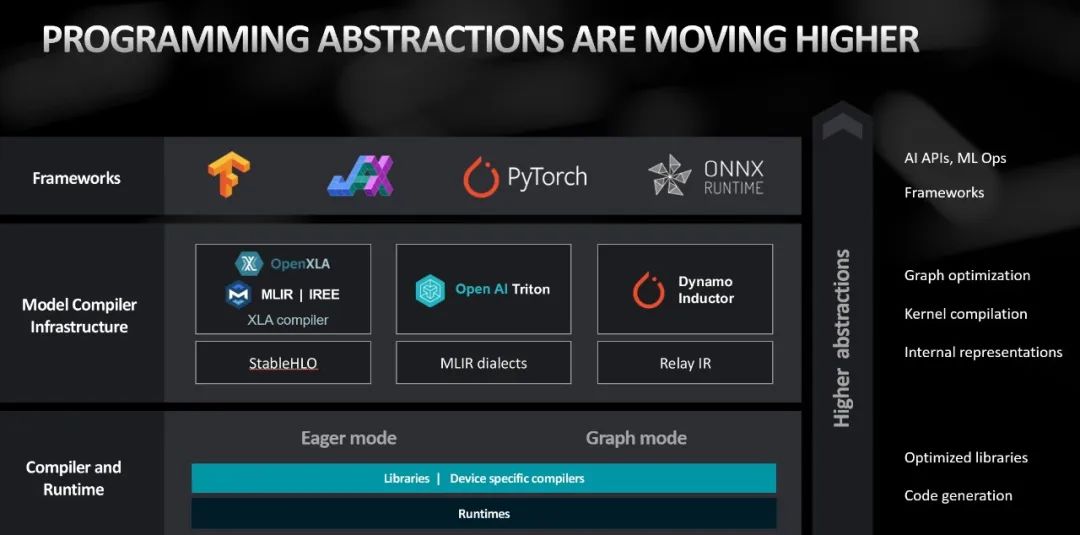
首先AI软件开发稳步提高了硬件编程的抽象级别。已经从用以前汇编或C编写的代码->线性代数库或卷积库等库->PyTorch/TensorFlow 等框架→转向位于框架之上的更高级别的API,获得最佳的开箱即用体验。
随着AI软件越来越有能力释放硬件的巨大进步,人工智能创新也出现了巨大的加速。自2018年以来,Transformer掀起了一场革命,出现了诸如ChatGPT推出等分水岭时刻。开放生态系统中也发生了大量此类创新:更大的模型、或更小的模型、模型得到微调、模型是多模式的、模型之间甚至相互交互,模型变得更加高效、模型与人类目标保持一致,模型变得值得信赖可靠。
随着创新的加速,我们既看到了挑战,也看到了绝佳的机遇。我们正在以开放和模块化的方式构建我们的软件解决方案,以拥抱更高层次的抽象并与开放生态系统紧密协作。在AMD,我们拥有三个软件平台:用于GPU平台的ROCm、用于XDNA AI引擎平台的Vitis AI以及用于EPYC CPU平台的zenDNN。AMD正在进行大量投资,以确保我们的客户在从更高抽象级别进行编译时获得最佳的开箱即用体验 。AMD也在开发统一的AI软件用于AMD所有平台,从而达到简化使用的用户体验。
我们正在这样做,我们正在取得的巨大进展,而且还通过与最重要的生态系统参与者合作,像PyTorch这样的框架和像Hugging Face这样的模型中心。举个具体的例子,基于我们与PyTorch的广泛合作,PyTorch 2.0在第0天就支持ROCm 5。与Hugging Face的合作正在帮助我们在所有AMD平台上运行各种AI模型。
这是我们GPU的软件开发栈,它是在GPU上做AI开发、运行和调整 AI模型和算法所需的一整套库、编译器和Runtime工具。AMD ROCm堆栈的很大一部分是开放的。我们的驱动程序、Runtime、调试器和分析器等工具以及我们的库都是开放的。ROCm 5拥有一整套优化,可提供具有竞争力的性能……算法和内核(例如flashattention)、新的降低精度的数据类型,以及新兴工具(例如Triton)。我们将ROCm连接到开放生态系统方面取得了重大进展,包括PyTorch等框架和Hugging Face等模型中心。以帮助客户在AMD GPU平台上快速移植、优化和部署其AI模型。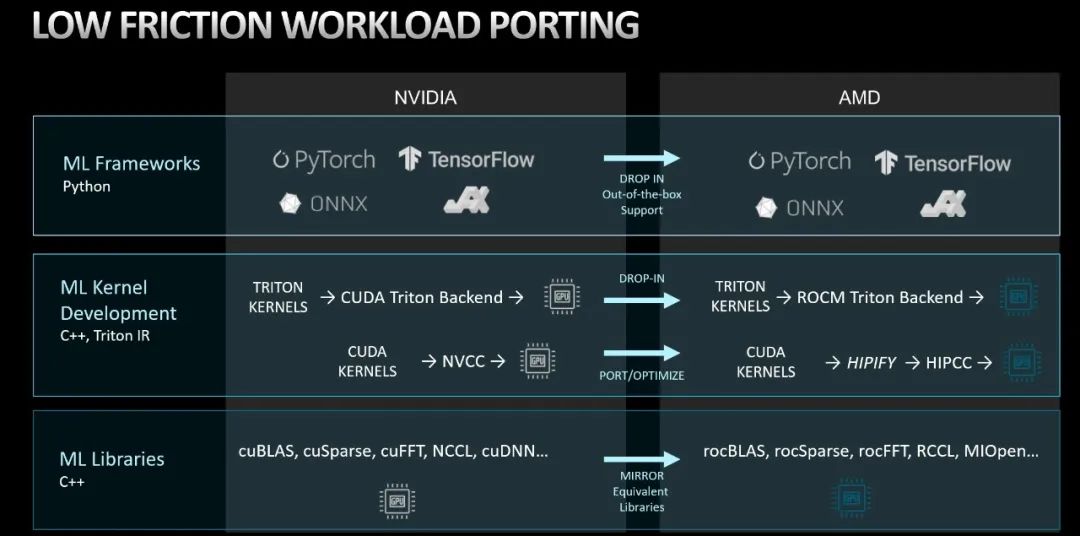
对用户来讲,他最关心的是从不同的GPU平台或者说友商的GPU平台如何迁移到AMD的GPU上?AMD提供与NVIDIA等效的库功能,由框架调用,在框架层面开发的用户可以获得“即插即用”的兼容软件体验。像基础模型构建者这样高度复杂的用户通常拥有一定数量的自定义内核代码,需要与AMD AI软件工程结合进行联合优化。HipiFY工具可让您非常快速地实现功能等效。致力于这些定制内核的性能优化。AMD已经与客户成功做到了这一点,并展示了在联合优化后达到与NVIDIA同等性能的能力。与此同时,AMD不断优化和改进我们的库。
这里是Mosaic实现无缝迁移至AMD GPU的成功案例,基于PyTorch 2.0和ROCm 5,ROCm直接替代CUDA,RCCL替代NCCL,Infinity Fabric替代节点内的NVSwitch。从而实现大模型训练在AMD MI250加速器上开箱即用,零代码更改和高性能。
我们来看一下AMD在的client侧AI软件解决方案。自从我们今年早些时候宣布该产品以来,ISV和用户开发人员都非常希望在我们的AI平台上开发应用的需求为了满足这一巨大的兴趣,我们在今年早些时候与 微软Build活动中表示,我们在微软的ONNX Runtime框架下提供我们的工具。这使得开发人员可以使用ONNX中熟悉的API进行模型部署。现在我们眼见为实,我给大家演示一下在AMD GPU平台,Ryzen AI平台上跑各种大模型。
这是在我们MI GPU上实现一个Stable Diffusion的推理,可以很快地图文生成,在毫秒级里达到这个目标。
展示我们在Ryzen AI笔记本电脑上实现多个AI应用时,提供有保证的QoS, 无抖动性能。同时实现人脸检测、深度估计、场景检测。这与其他需要以分时方式共享AI计算资源的AI架构不同。
另外,我们今天也提到,AI已经从云到端,甚至是混合式AI。我们的解决方案,不仅可以在云上去做这些大模型,我们也可以在端侧、在我们的笔记本里面去做这些大模型。这个例子就是我们用MI系列GPU,实现了一个700亿参数的大模型,实现图文生成图文。这个是让它写一个有关旧金山的诗文。在我们端侧,我们是跑的是OPT模型,实现文字生成。
我们基于Radeon架构,不仅可以实现3D渲染,同时可以做AI的训练或者推理,快速平稳地进行加速。AMD会继续地加大AI的投入,将强大的AI处理能力的产品引入云、边缘和端,并且我们致力于与广大AI开发者,社区一道提供开放的AI软件生态系统,与广大AI开发者、用户,同超越,共成就。这就是我今天与各位分享的所有内容,感谢大家宝贵的时间。以上是王宏强演讲内容的完整整理。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

