芯至科技尹文:拆解架构创新四大路径,打造10倍性价比大模型推理芯片丨GACS 2023
芯东西 | 2023-10-09 08:31:38 阅读:269
 发布文章
发布文章
解读AI大模型推理“芯”机会,RISC-V、一致性总线、WoW的架构创新大有可为。作者 | GACS9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳市南山区圆满举行。在9月14日AI芯片架构创新专场上,芯至科技联合创始人、首席芯片架构师兼副总裁尹文分享了主题为《AI计算新时代催生芯片架构走向“算力统一场”》的主题演讲。尹文认为,进入AI新时代,算力创新不再仅仅是单个处理器微架构和芯片工艺的创新,而需要软硬件全栈的系统架构全面创新,未来的创新机会来自以下方面:开放的通用指令架构,高效的融合加速器,异构互联总线和芯片工程,开源算子库、工具链和软件。1、AI大模型落地到推理侧的新机会与RISC-V架构创新不谋而合,RISC-V不仅可以做标量通用计算,也可以做线程级并行的AI计算。Scaler小标量+SIMT大算力的指令集/微架构融合将是未来RISC-V发力的重点,能以相对低的成本,为AI推理侧应用提供高效支持。2、SoC芯片系统的有效算力依赖于计算核心或计算Die之间的高效互联,通用算力和异构算力需要在整个系统的内存从逻辑上可以被统一为一个更大的具有一致性的空间。低时延大带宽的一致性总线互联可以让异构计算芯片更好更紧密的协同,从而提高整个系统的性能和能效。3、WoW (Wafer on Wafer)混合键合在新型芯片工程技术领域有重大价值。在他看来,WoW可将AI Die和Memory Die垂直堆叠,以低于HBM一个量级的成本提供数倍于HBM的带宽;对于大模型推理来说,4~6GB的Memory Die完全满足Transformer一层网络权重的存储和层内高带宽需求。基于此,芯至科技围绕RISC-V开源指令架构、自研一致性总线、WoW 3DIC的架构创新,可以带来10倍性价比的大模型AI推理芯片。展望更长期的未来,尹文相信基于RISC-V开源指令同构和微架构异构,开源软件工具链及自主一致性总线和芯片工程创新,未来有机会推进到算力统一场。算力统一场将更利于形成更大的自主可控软件新生态,并符合计算架构的原始特征,助力我国在计算体系方面换道超车。以下为尹文的演讲实录:首先谢谢主办方的邀请,还有各位同行、各位嘉宾的参与。自从今年上半年大模型层出不穷,从芯片架构领域,各位同行都在一起讨论,未来芯片在AI领域的架构怎么做、未来新的机会在哪里。今天我给大家带来的演讲就是我们团队在这一方面的思考。
01.AI新时代对算力发展提出新要求:软硬件全栈的系统架构全面创新
进入AI计算的新时代,怎么催生芯片架构不停地往前推?推向一个什么样的地方?我们提出了一个“算力统一场”的概念。首先看芯片架构的创新,摩尔定律的一个根本特征就是单位性能的成本在线性下降,但最近几年,单纯凭工艺,到5nm、3nm之后,成本下降并不是线性的。我们怎么样去延续这个线性的性价比的降低?更多地是要靠软硬件重构。重构的一个顶层思想其实是来自第一性原理,要把原来的架构不停地分解,再不停地重构。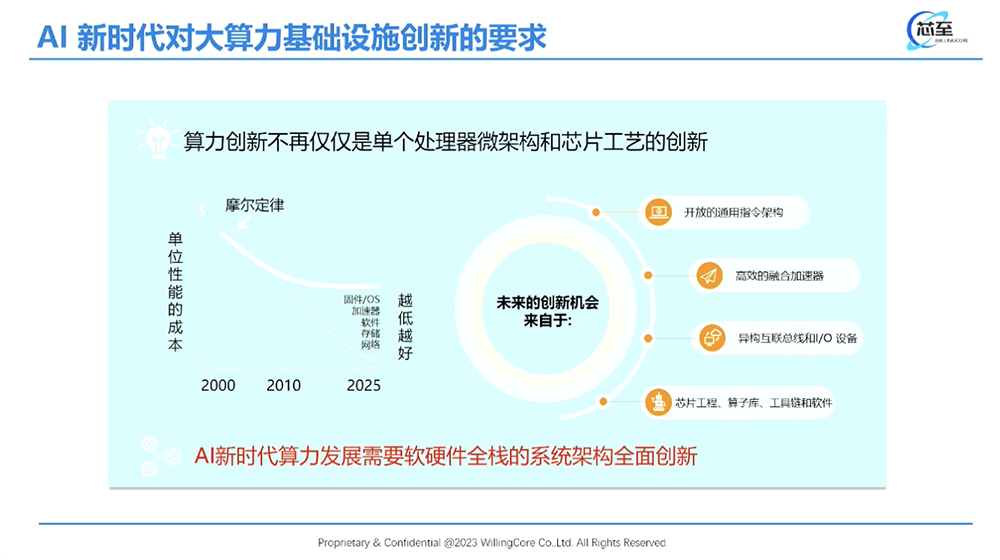
从芯片架构的角度来看,我们看到了几个机会:第一个是开放的通用指令架构,上个月(8月份)在北京的RISC-V峰会,各位同行有很多的讨论,RISC-V就是开源开放架构的典型代表。第二个是怎样做一个高效融合的加速器。大模型应用需要底层适应这些模型的算力架构,算力架构怎样融合在通用指令架构上,这是我们所面临的机会,也是一个技术难题。另外,现在处理器核越来越多,多Die互联、异构互联、存储的连接越来越复杂,怎样有一个异构互联的高效总线,还有高效互联的I/O设备的一个新架构,是未来AI芯片架构的一个新方向。最后,芯片的晶圆和Die越来越大,功耗越来越大,在提升它的性价比、能效上需要一个非常强大的、可演进的一个芯片工程的支持,以及整个算子库、工具链和软件的发展。
02.AI大模型推理新机会,与RISC-V架构创新不谋而合
大模型和RISC-V在最近几年有很好的结合,算法、算力、数据三架马车要齐步往上推,我们看到,在微架构和模型方面是同步发展的。左边的图是大模型在快速发展,云端训练的大模型有点类似于一个人,首先从0到1,经过九年义务教育,形成完整的世界观。未来这些大模型要在各行各业去应用,就好比大家上了大学,选定一个专业,进入到一个行业。有句话叫“学好数理化”,数理化就是基础,未来模型要不停地增加行业知识,那是一个fine-tuning(微调)阶段,意味着更多的机会,大模型在各个行业能够不停部署,产生真正的市场价值。
从右边的图可以看到,RISC-V的Scaler部分,有一个通用开源的超标量架构,可以帮助我们打造在处理器主机端的软硬件栈的基础。另外基于RISC-V的BSD协议,它有非常广阔的指令扩展空间。在上面绿色和紫色的部分,我们可以自定义Vector(向量)、Tensor Core(张量核)这些单元,这是RISC-V的指令框架所允许的。然后我们可以在这个扩展指令框架下,去实现各种各样的微架构,微架构就是芯片架构所具体实现的电路,包括矩阵乘、卷积等电路。RISC-V所带来的一个很大价值是上游性价比的急剧提升。举个例子,大家可能不知道对OpenAI的Triton是否熟悉,现在有很多年轻的朋友正在利用Triton这个工具来做AI算子自动化的开发。Triton有全开源的优势,另外它可以通过自动化的生成工具,来生成特定的一些算子,比如说浮点的卷积或者是矩阵乘。基本上它的效率和手写的算子库效率是相当的,比如说一个FP16的矩阵乘,一个Python的代码可能就20多行,大家可以在网上找到很多例子。它支持像Python这样的高级语言,可以极大降低通过自定义指令学习类似CUDA这样编程框架的成本。按照现在Triton的发展,相比CUDA,它在自动化算子生成、内存优化、SM核心的scheduling等方面有很好的效果。
Triton目前是和整个RISC-V的生态圈、全球大的趋势同步发展,发展速度非常快。另外它也可以避免不兼容的指令,因为RISC-V整个行业在推进,在生态建设上是齐头并进。我们基于传统的GPGPU方案会有大量自定义的算子,并且要开发自己的编译器。作为一个芯片公司,其实我们在软件的投入上反而会更大,包括在工具链、算子库的开发,很多软件开发团队可能高达70%~80%的规模。如果采用开源指令和开源工具链这样的技术路线,首先RISC-V可以复用整个编译器的开放成果,另外在客户支持、算子开发这方面,有类似于像Triton,还有未来会发展更多的开源工具,可以自动化地生成第三方算子,极大降低软件开发的人力成本。
03.一致性总线使通用和异构算力紧密耦合,大幅提升有效算力
算力效率方面,我们提到了“有效算力”概念,跟芯片效率是非常相近的概念。现在我们做芯片架构的时候,在关注单核的算力、主频、流水线的能力。并且我们还要看在一张晶圆上可以做多少Chiplet的Die,Chiplet集成得越多,算力、核数也会越多越大。但大家可能忽略了一点,就是我们的SoC,把那么多核互联起来,包括die-to-die的Chiplet互联,还有CPU和GPU这样类似于NVLink、CXL这样的异构互联,它的效率问题。我们要关注这么几个指标,包括总线的时延、带宽、一致性的能力。可能大家对一致性的理解不是特别多,它就好比部门越来越多,虽然团队的实力和规模越来越大,但是并不代表这么多团队产生的有效绩效能够越来越强,需要各部门的互联互通、能够目标一致。这个一致性也是一样的,我们有那么多的CPU核、AI核,包括同构、异构的核,怎么保证处理任务的一致性。最后是功耗,它的能效也非常重要。
当前业界在总线方面的发展,包括Die内的Ring/Crossbar总线架构,还包括最近英伟达在Grace芯片里自研开发的Scalable Coherency Fabric,都是在总线上面的一些技术探索。刚才很多同行也介绍了die-to-die(D2D)、Chiplet、并行、UCIe等各种D2D互联总线,怎么样提高它的效率,以及我们在一个大的集群里面怎么样把异构的芯片通过Switch互联起来,这更多是一个系统上的概念。一致性总线最终的目的是为了通用和异构,就是各种算力能够有效互联,来提高它的有效算力。
04.芯片工程新技术突破内存墙瓶颈,极大降低带宽成本
说完互联墙,接下来就是大家谈论比较多的内存墙。在AI芯片,我们当前的方案更加依赖于HBM这种大带宽的内存。HBM跟CoWoS相结合,在扩展带宽的时候,线性扩展带来成本的极大增长。怎么样把AI的逻辑Die跟内存Die有更紧密的连接,把带宽成本降下来?现在我们可以看到,Hybrid Bonding异构键合技术在快速发展。基于Hybrid Bonding技术,我们可以实现Wafer-on-Wafer(WoW)的垂直互联,就像从三楼到四楼可以有上万部电梯,这样我们会场这么多人,吞吐率就会非常大。我们芯至科技和合作伙伴一起,现在已经可以做到在两个Die有70000多个pins互联,相当于有这么多部电梯互联互通,容量可以做到6GB,相当于我的AI逻辑Die和内存Die可以实现非常短距的、大带宽的互联互通。
由于我们可以不用那么大的die,我们可以极大降低WoW这样一个内存架构的成本,从计算效率来看,虽然HBM的容量比较大,但实际上在大模型Transformer方面,网络是分层的。可以看右边的表格,刚才提到大模型未来进入行业部署更多是微调,它的模型参数并没有像ChatGPT或者GPT-4、5未来指数级的增长,单层参数量可以放在WoW这样一个DRAM存储空间上。在容量够的情况下,实际上就可以体现WoW这样一个大带宽的巨大优势。
05.围绕三大方向构建创新架构,打造约10倍性价比优势的大模型推理芯片
小结一下,在AI架构创新方面,作为芯片架构师,我们还有很多事情可以做:一方面,开放的指令架构。我们可以重新来认识一下RISC-V,它可以做CPU,大家可能熟知的是x86指令、Arm指令,RISC-V就是下一代新生的CPU指令架构。但我们基于RISC-V也可以做SIMT的架构,实现GPGPU的功能。在通过RISC-V做GPGPU的过程中,我们可以最大地复用RISC-V这个开源指令,包括它的开源工具、整个软件复用度,就可以极大降低在做自定义芯片的情况下,我们要有大量的人力成本。第二,高效的异构互联,在自研一致性总线方面,我们更多要有一个系统框架,怎么样把Die内的互联、D2D Fabric、整个Chip-to-Chip的互联纳入到一个完整的一致性框架下,并且在物理上、在芯片工程上降低时延,提升带宽,这是我们要发力的重点。第三,新型的芯片工程,在内存墙方面,我们怎么样把AI Die通过WoW、Hybrid Bonding这样的技术,把带宽做上去,未来是能够替代HBM、CoWoS封装等高成本方式的最佳途径。所以我们团队现在在考虑,在当前的大模型推理芯片架构上,在软硬件结合还有芯片工程上的创新,来打造具有10倍性价比以上的创新芯片。
06.结语:重构计算体系结构,打造算力统一场,发展软件大生态
中长期愿景,算力统一场。首先可以看到中间这个图,在整个RISC-V指令规划基础下,我们在这个圆圈的内部可以做很多事情。
我们的DSA和通用架构,实际上是一个循环,在80年代的时候,当时一个叫牧村的日本人提出的“牧村定律”,就是从专用到通用这个循环的规律。RISC-V的整体指令架构是统一或同构的,但我们可以在微架构做很多事情,包括SIMT、DSP、DSA的核心等,来发挥RISC-V在整个开放指令上的优势。另外一点,开源工具链,就像我刚才给大家介绍的OpenAI所做的Triton的例子,大家可以多去看看,Triton在整个社区非常活跃。未来会有更多像Triton这样的开源工具发展,结合RISC-V微观指令的发展,在整个指令、自定义算子、编译器方面,有很大的性价比提升。从微架构异构和指令集同构、开源工具链、在SoC层面的一致性总线还有芯片工程方面,我们有机会在未来打造一个软硬件同构的新生态。这个新生态更加有利于在国内形成一个更大的、自主可控的软件生态,并且在芯片架构领域更加符合计算架构本身原生态的架构,有助于在计算领域帮助我国在计算体系方面做到换道超车。大家知道当前的CPU、GPU的计算架构和生态是建立和发展主要在国外,国外特别是硅谷有很多行业前辈奠定了在传统计算架构上面的基础。在未来算力统一场的新方向,我们可以做很多自主可控的架构创新。在AI新时代新机遇的引领下,希望我们团队和整个芯片行业同仁一起,能够把算力同一场的愿景不断地做好、做远,共同实现计算新生态。谢谢大家!以上是尹文演讲内容的完整整理。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

