
芯东西9月28日报道,9月14日~15日,2023全球AI芯片峰会(GACS 2023)在深圳南山圆满举行。在首日开幕式上,清华大学交叉信息研究院助理教授、北极雄芯创始人马恺声分享了主题为《Chiplet架构在AI芯片中的商业价值》的主题演讲。
今年2月,北极雄芯发布了国内首款基于异构Chiplet集成的智能处理芯片“启明930”。该芯片由11块Chiplets通过高速接口拼接而成,采用12nm工艺、2.5D封装、全国产基板材料,可独立用于AI加速卡,亦可通过D2D扩展多种功能型Side Die进行集成。
Chiplet是后摩尔时代提升芯片性能的有效路径,能将多异构集成的模块拆分用不同制程制造。以下为马恺声的演讲实录:
各位领导、各位专家、各位嘉宾:大家中午好!
我来自清华大学,也是北极雄芯的创始人,跟各位汇报一下我们这几年的一些工作和想法。我的题目是《Chiplet架构在AI芯片中的商业价值》,我会讲一些技术部分以及Chiplet的好处,包含四个部分:从历史到价值,再到愿景和我们的想法实践。
说起Chiplet,早在1969年摩尔老先生的论文里就提到过。2018年我注意到这句话,然后去论文中扒下这句话:It may prove to be more economical to build large systems out of smaller functions,which are separately packaged and interconnected(用较小的功能构建大型系统可能更经济,这些功能是单独封装和互联的)。这是论文里某一段的第一句。
进入到商业层面,我们很早就意识到一个问题,光刻机的尺寸为26mm×33mm,更先进的光刻机尺寸更小。摩尔定律到了尽头之后,我们没有办法做小芯片,只能把面积撑大,但光照的面积就这么大,所有良率只能这样。第一个解决方法,就是整个同构互联起来,这是为了解决光照最大尺寸的问题,二是解决省钱,异构的拆分通过复用可以更好地解决这件事情。
其中Wafer to Wafer(晶圆至晶圆)、Chip to Wafer(芯片对晶圆)的集成等工程问题,通过在座各位封装专家的努力就可以实现。
这里面真正有挑战的是散热,把多个晶圆堆到一起,中间的那片晶圆的热量导不出来。一旦热导不出来就会降频,需要控制它散热防止温度越来越高。所以解决散热最简单的方案,就是做架构拆分,比如这一块是热的,下一块晶圆就不应该让它热,这样交叉起来,但这个事情非常考验架构设计人的能力。
还有野路子,我们可以通过打更多的TSV把热导出来。但这个路子的问题在于,因为TSV是在硅上面穿孔,这会导致孔打多的话,热应力系数不一样,使得很脆的硅一不小心就会爆掉。
还有可能的方案是把微流道进芯片。
Chiplet真正带来的好处,我前面已经稍微提到了。
从1965年开始到2005年一直在提升芯片频率,可以看图中绿色的线(如图),到2005年频率提升不上去了。很快,2000年初,我上学的时候第一款手机是联发科的八核手机,当时还不理解手机为什么要上八核。
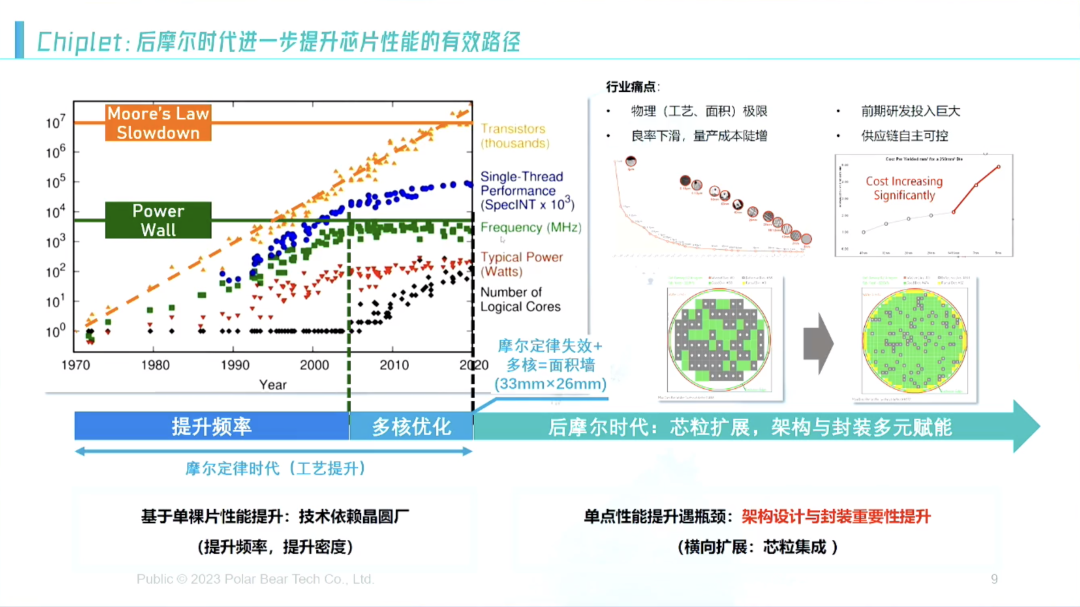
到2005年起,核的数量越来越多,2020年之后,摩尔定律基本上发展到黄昏。我们发现另外一些问题,摩尔定律即将走到尽头我们面临的问题是什么?
5nm、3nm、1nm只有二十几个原子,但晶圆代工厂给出的报价很高,其中,量产的价格5nm一片晶圆要2万多美金左右,12nm差不多六七千美金,价格翻了一倍,性能只涨了百分之几十。所以这件事情不划算。
另外还有一些问题,大芯片有大芯片的问题,大芯片面积大了之后良率很糟糕,因为上面只要落一个点,这块芯片就要扔掉,所以良率自然很糟。
另外还有一个问题,芯片是方的,晶圆是圆的,所以边上会浪费一圈。但芯片小的话,浪费这部分相对就少很多,所以小芯片有天然的优势。
因此,我们就在想,什么样的形式能做这件事情?有一个大约的参考值,这些值都是相对比较准的。如果600平方毫米是33%良率,100平方毫米良率在80%左右,那么这是一个巨大的差异。并且国内晶圆代工厂的水平还有差距,所以将33%的良率提到80%,成本变成原来的一半以下,这件事情有非常大的好处,所以我们希望把整个东西拆散。
另外Chiplet还有一些好处,我们以前都是找晶圆代工厂、自己做库、买IP,最后把东西堆出来。如果市场上有一些东西,我们是不是可以从供应商ABC处采购一些半成品,比如亿铸科技的ReRAM,然后集成上去得到很好的能效比,类似这样的方式其实可以做很多异构的集成。
此外,I/O真的有必要上3nm吗?为什么不用7nm、14nm搞定?因为模拟电路在这部分能取得的性能非常有限,甚至漏电更差。
还有一些诉求,CPU每年迭代吗?但性能提升仅在10%-15%之间,NPU也每年迭代,这样的话,我们每一次迭代都要把所有东西全部重做的压力很大,所以,为什么不能把NPU独立出来?然后将其每年迭代,但其它I/O的部分就不动了。
Chiplet还有一个非常大的好处,就是Scalability(可扩展性)特别好,通过增减HUB的数量就可以做出不同系列的产品,以前这件事情需要做高中低档次多块芯片来实现。
当然,Chiplet的好处主要还是集中在大芯片、先进制程方面,(如下图)横坐标左边第一个是SoC、MCM、InFO、2.5D,纵向看是5nm、7nm、14nm,上方横坐标是两个Chiplet、三个Chiplet、五个Chiplet。你会看到,越往右下角,先进封装的东西对比最左边的条,能省的钱越来越多,最右下角能省到50%。
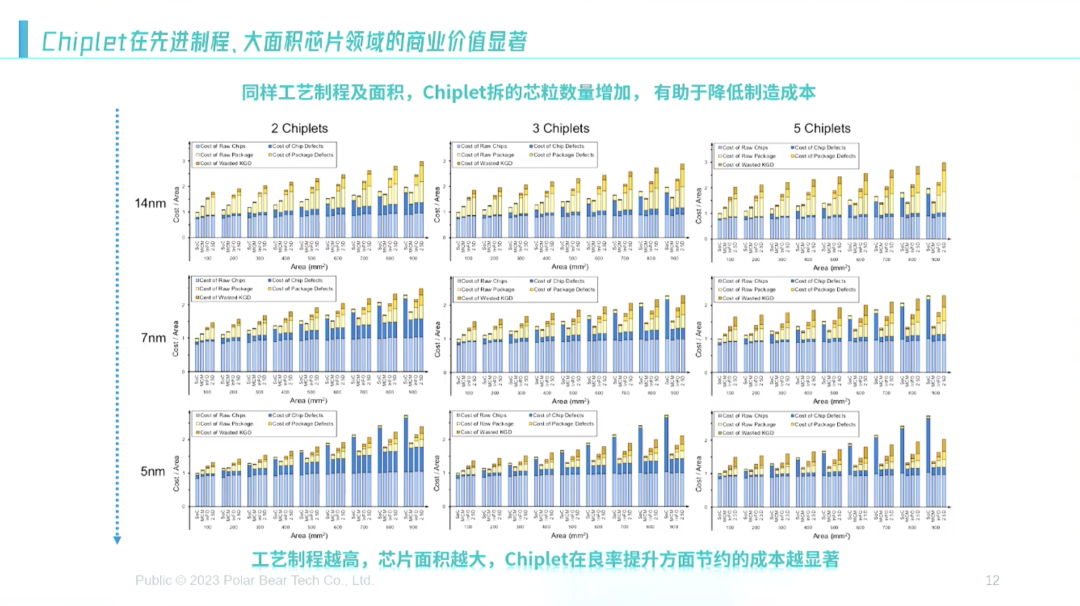
但这里面也要看芯片的面积,先不说100平方毫米,但三四百平方毫米之后越大越划算。做一个小耳机的产品,从钱的角度来讲可能不划算,但它如果有体积小等其他的诉求就可以适用。
我在清华交叉院,我的院长是姚期智先生,“姚班”是国内AI研究的高地,也是AI理论、量子、AI+的高地。
从2018年开始,我在做的事情就是给院里的老师做芯片。我进来第一件事就发现,清华交叉院有30个老师,基本上每个老师把持一个方向。所以我就在想,如果三年做一块芯片,我现在30岁出头,我发现我的人生路线很清晰。
所以我一直在琢磨,怎么能快速地给这些老师做芯片?能收敛出来的东西就是:我能不能把它抽象成异构的集成形式,把一些共用的部分(C)放中间,然后把不同的东西(X、Y)每换一个行业就单独做一小块,再结合起来(如下图)。
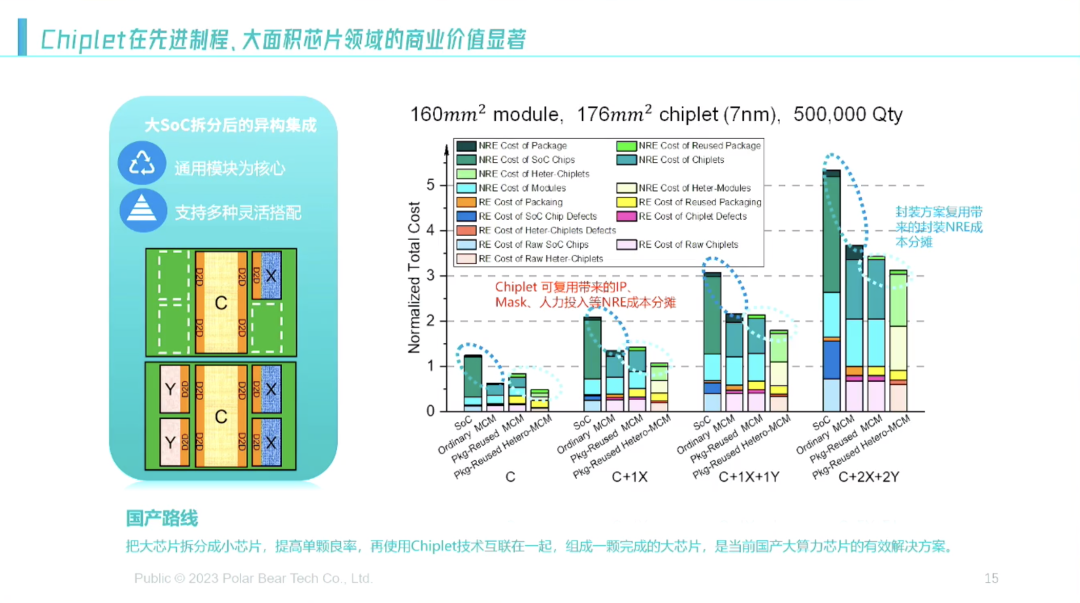
用这种形式,不管是IP、掩膜还是人力的投入都可以得到巨量的节省。这是我的一篇文章,这里面把到底能省多少钱的帐算得清清楚楚,大家可以去搜索浏览。
另外我们自己开发接口,此前我想的很简单,市场有很多Die to Die的接口,可以根据需求购买。但我后来发现,有一个问题是,没有一个接口适用所有的封装,2D或2.5D封装的产业链都差异巨大。所以我们自己做接口,然后将两个连起来,这解决的是面积问题。
但我们真正感兴趣的是右边这种形式(如图),我们希望中间的I/O或者HUB的形式是通用的,能满足大家基础需求。比如AI、隐私计算、制药等应用,企业可以自己做一部分,然后我们提供整套解决方案或者接口、封装,大家可以自己选择。
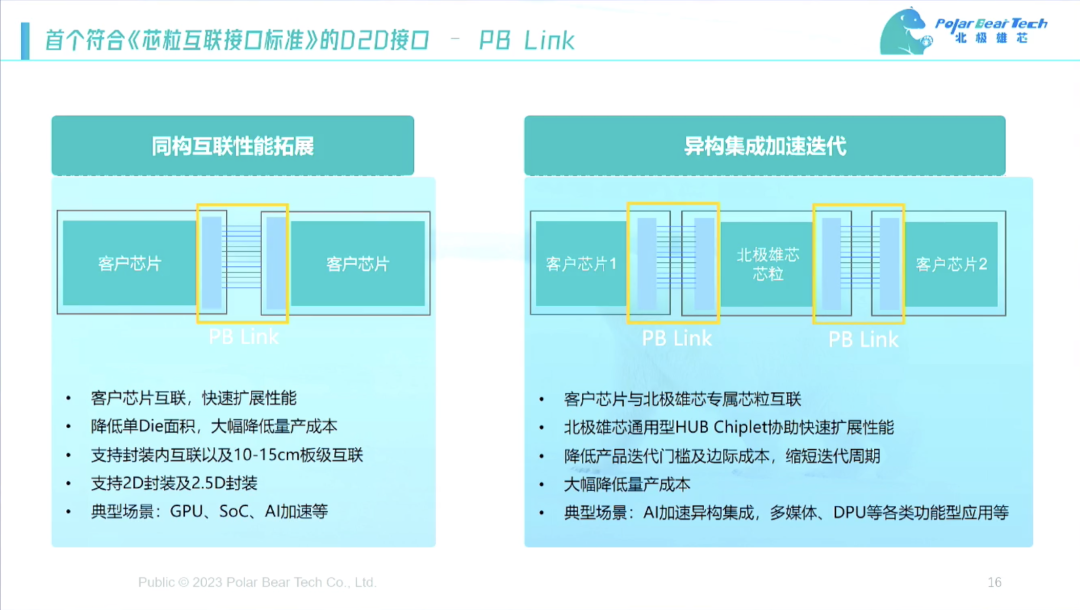
我们的整体目标就是希望降低整个行业在做专用计算时候的投入和需求。我们自己把它做出来,这个接口已经做得很完备。中间的图是FF corner,我们所有corner全部都做,真正做温箱从-40度拉到125度,因为产品的应用在汽车上。

接口整个采用高通道高速SerDes的方案,12nm工艺、大约面积为2.8平方毫米、支持2D和2.5D封装,并且整个封装采用全国产的产业链。
然后我就请姚期智先生一起,将这个接口以联盟和团标的形式发布出来。值得注意的是,这个产业联盟(中国Chiplet产业联盟)在2020年9月成立,2022年3月,UCIe成立Chiplet这件事情变火,所以我们其实早于它。
我们意识到这件事情之后,就把整个芯粒互联的接口标准以及车规的互联标准都开放出来,然后和制车厂一起把这些东西跑通。
我的目标就是创造高性能计算的新范式。
北极雄芯在这里面偏商业化一点,我们从2018年开始一点点做,直到2020年9月,我们和封装厂耦合了一段时间后才把整个东西搞清楚,2021年成立公司。现在,我们有量产的产品、能实现收入、把“930”发布出来,这就是整个公司发展的简单回顾。
真正的架构长这样(如下图),我们称作通用型HUB Chiplet、Functional Chiplet方案。
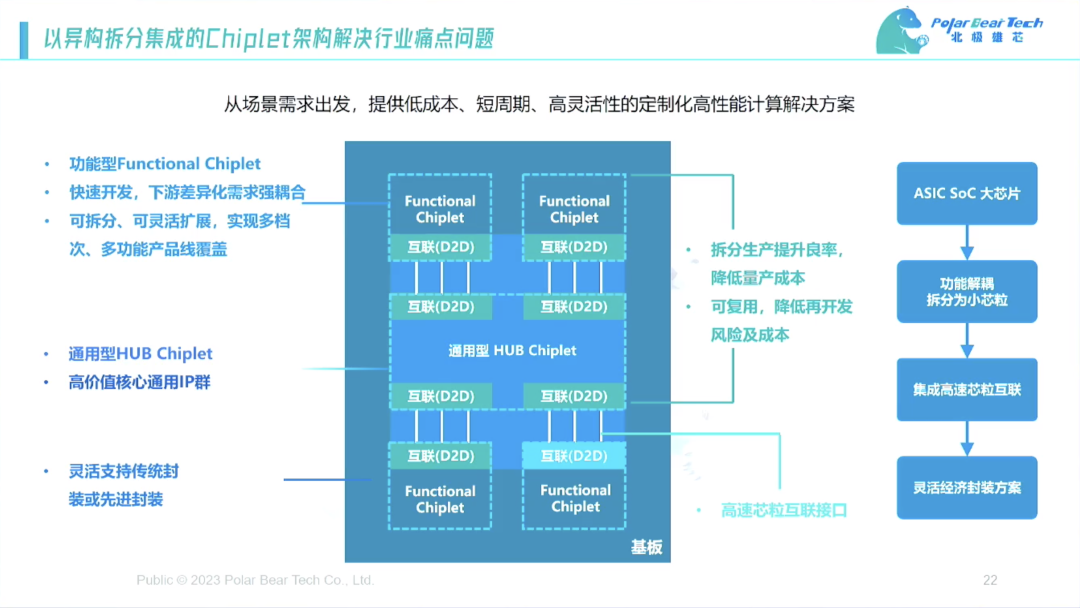
在HUB里面,我们放了大家能想到的高端通用IP,如PCIe 5.0、LPDDR5这样的IP,我的目标是HUB使用时长能达到五年。
除了HUB,我们还限定了功能模块面积不超过100平方毫米,因为我们发现面积超过100平方毫米,良率会往下掉得非常严重。大家算一算,如果一个HUB差不多一两百平方毫米,Functional Die拼四个,实际上能拼8到16个,比如拼8个加起来有800平方毫米,甚至1000平方毫米,其算力实际上很大。
用这种形式,我们就可以把专用和通用拆分出来,客户有诉求可以选我们的接口,也可以选其它接口,然后将其连起来。还有其他客户的东西,我们也可以帮忙导入。
所以从解决方案到接口到封装,我们可以提供全套的解决方案,也可以根据大家的需求来做,所以我们能真正把这款芯片做出来。
这是我第一次在公开场合把这张图(如下图)抛出来,它非常复杂,由11块Chiplet拼在一起,采用2.5D封装,纯国产工艺。

这件事情我做了三年,从2019年开始一直在和封装厂耦合。不瞒大家说,国内的封装在一些基板技术上有差距,中国台湾的技术能做到30层基板,国内能量产的水平差不多在8到10层。
这是为什么?因为其是一层膜,做完一层铺一层膜,一层良率99%的话,做30层就是0.99的30次幂。因此,我们选择自己做,将11块拼在一起,左右可以是NPU,上下可以自己定义,用这种形式可以将其做起来。北极雄芯真正的Know-How就是用更复杂的接口换取了对更差封装的容忍。
给大家举个例子,底下蓝色的叫基板,如果有30层布线随便布,但我们现在仅有6到8层基板,扣去两层电源和ID就剩4到6层,所以没有足够的位置布足够的线。
所以我们只能把提升单根线的速度,这就遇到另外一个问题,单根线的速度上来之后,一个接口只有38根线,一共380根线,对比苹果10万根线是巨大的数量级的差距。
单根线的速度频率比较高,但这个解决方案的问题是什么?用高速串口,可以想象成射频领域,射频对基板的要求很高,需要防止毛刺、差损、回损对接口产生影响。
因为普通的并口200兆只需要连接就可以,高频率就会对封装有要求。所以我们真正做的事情就是跟国内所有封装厂做封装,把参数提取出来,再看国内团队有没有能力把这个接口做完去适应这套封装,把其中的差距补回来。
当然这套方案也存在问题,例如高速串口的带宽可以支撑,但串口的延迟相比于并口延迟会更大。
这种方案好处在于:首先,其基本上能用国产的供应链,采用CoWos先进封装仅20%-30%的成本,做出同样性能的芯片。
二是这些东西要跑通,还要看最后的系统利用率,如Die to Die能拉多少?算力可拓展吗?以及将整个供应链都跑通后真正给最终用户送样。
北极雄芯的主要客户很多是主机厂和板卡供应商,所以这些网络都是他们提出来的。我们真正将厂商的软件栈跑齐、验证后发现整个利润率差不多在60%左右。
我们有一套软件工具,这套工具跟前面大厂提的看起来好像一样,但实际上有50%的东西是完全不同的。
它们不一样的地方在于,我们的方案中间是一个HUB,边上挂了10个Chiplet。这样就有一个问题,从硬件封装的角度来说好像只要连接上就可以,但如果从软件或者算法的角度看,假设每一个小的东西里面都是一个Mesh,比如每个都是小的计算单元NPU,从上往下看就是一个巨大的Mesh,但是在画虚线的地方是Die to Die的接口,这里面的传输功耗相对比较小,一旦越过Die to Die,就会有延迟,且有功耗代价。
因此,我们发现它会把这件事情切得很小,原来我想得很简单,以这个为例(如下图),这是一个ResNet 18的网络,我将其一层层摆下来后发现这种形式不行,因为它越过这层线功耗就会变大,比SoC糟糕3倍。所以我就意识到第二个问题,能不能“之字型”绕起来,这也是一种解决方案,但我后来发现这个方法也不行。
实际上现在北极雄芯内部,真正的另外一个Know-How就是在编译层面,这个策略有AI的方法,也有暴力的办法。
我举一个例子,以这张4×4的图为例(如下图),我想在里面尽可能做到复用,排出来的最好形式就是第二张图,第三张图是机器搜出来的最好方式,这个东西刚开始我无法理解。其中,第0层、第1层等是散的。当我们回头测算时发现,用这种形式其网络内部复用是最好的,没有跨Die或者跨Die的数量搬运很少,用这种形式基本上能跟SoC的功耗拉齐。
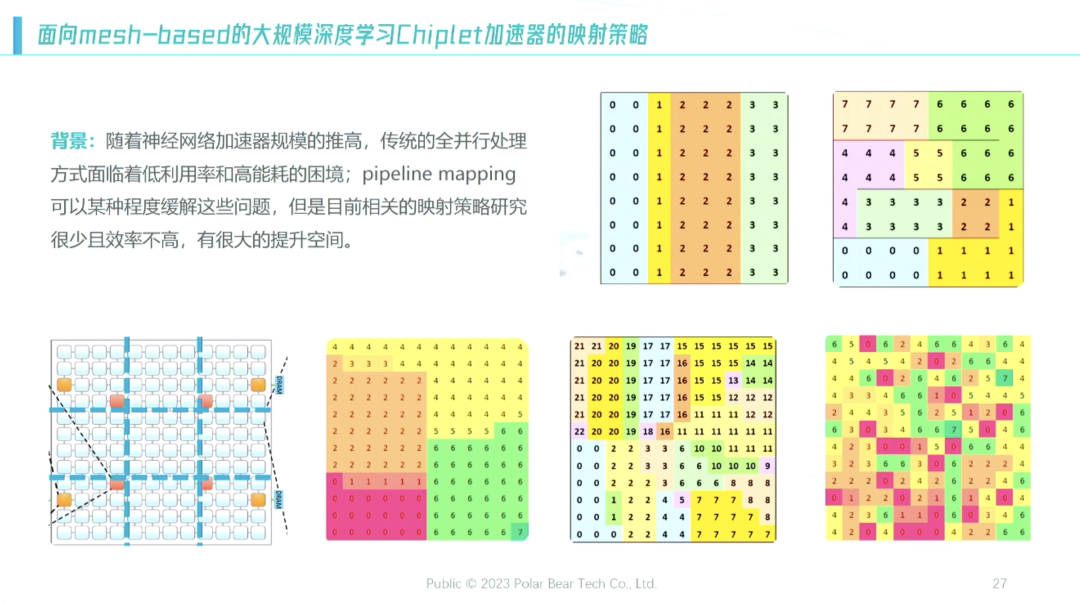
因为这里面有很多事情要做,比如鉴定这块复用、如何做数据交换、这个角的数据最好不要跟那个角的数据交换等,用这种形式我们就可以把整个功耗压到相当低。Chiplet带来的芯粒税问题,包括接口带来的问题,用编译的角度能将其影响降到最低。
北极雄芯正在做的就是把整个东西打散,按照不同的模块再规划起来,重新梳理数据流,采用国产供应链全部封装起来,做成板卡把芯片跑起来,给最终的客户送样,并且能在芯片上把多个网络实时并行跑通,这件事情是过去北极雄芯在过去四年做的事情。
我的演讲就到这里,谢谢大家!
以上是马恺声演讲内容的完整整理。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

