
▲瀚博半导体AI大模型演示展台
当然,这一风向并不令人意外。连权威AI基准测试MLPerf最近都新增了大语言模型和推荐算法两项新的基准测试,足见跑AI大模型的速度已被视作衡量芯片性能的重要指标。得益于此,今年AI芯片展区明显要比往年更加热闹。随着更多国内AI芯片成功流片与量产,AI芯片企业们比拼的赛点,已经从单纯的性能指标转向进入真实应用场景落地的较量。▲高通获颁SAIL奖
超10亿参数Stable Diffusion模型能够在搭载第二代骁龙8移动平台的安卓手机上运行,实现15秒内20步推理。燧原科技面向AIGC模型训练的液冷集群云燧智算集群摘得了“SAIL之星”奖。该集群采用的燧原科技邃思芯片曾获2022年吴文俊人工智能专项奖芯片项目一等奖。
▲燧原科技的一系列里程碑式产品
云燧智算集群产品已在国家级重点实验室之江落地千卡规模训练集群,提供超过100P的先进AI算力,能高效支撑融媒体、文本生成PPT、跨模态图像生成等AIGC应用以及多种AI4S科学计算应用的开发和前沿探索。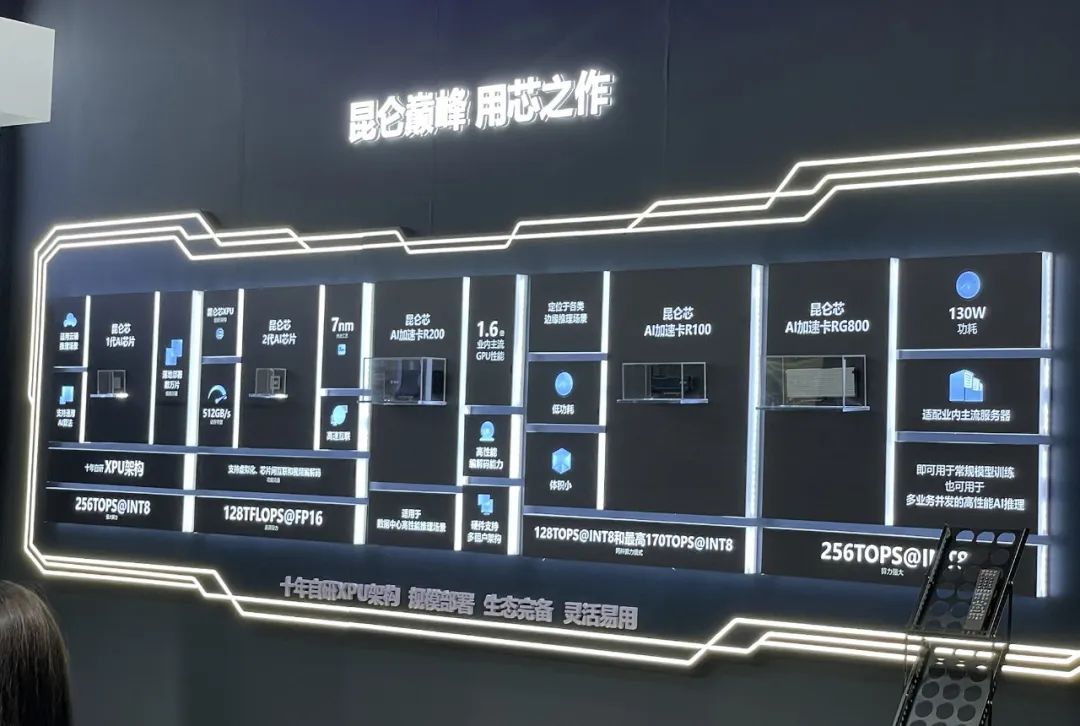
▲昆仑芯历代AI芯片及AI加速卡
在此次WAIC上,针对不同参数级别的昆仑芯第二代系列产品矩阵首次亮相,包括3款昆仑芯AI加速卡R100、RG800、R200-8F。其大模型端到端解决方案更是继正式发布后首次参展,该方案在能源行业、文心一格、智源研究院等多个场景均有应用落地。其中,R200-8F面向百亿以下参数量级,性能可达到主流GPU 1.2倍且价格更有优势;R480-X8加速器组针对百亿到千亿参数量级,大内存和芯片互联的技术使其性能达到同类型GPU的1.3+倍;千亿参数,可采用昆仑芯R480-X8集群,实现多机多卡分布式推理。天数智芯自称是国内首家真正量产的通用GPU企业,从2018年开始设计通用GPU天垓100至今,已有两款产品成功进入量产阶段。据悉,截至2022年底,天数智芯累计订单接近6亿元,去年全年收入大约2.5亿元。
▲天数智芯通用GPU产品展台
另一家国内通用GPU领军企业登临科技自认是国内首家完全凭借自主创新,实现规模化商业落地的通用GPU企业,通过GPU+架构创新,解决了通用性和高效率的双重难题。经过大量客户产品化验证,针对AI计算,GPU+比现有主流GPU在性能及能效上有显著提升。首款基于登临GPU+的AI加速器Goldwasser(高凛)2021年量产投入市场,2022年销售过万片,应用场景覆盖互联网、智慧城市、电力、能源、金融等领域。高凛二代产品在2022年流片, 在2023年实现量产。根据现有客户测试结果,二代产品针对基于Transformer类型的模型提供3-5倍的性能提升,能够大幅降低类ChatGPT及生成式AI应用的硬件成本。今日上午,登临科技还宣布了一个好消息:获得中国互联****资基金独家投资。
▲登临科技Goldwasser(高凛)六大亮点
▲瀚博SG100芯片简介
VA1L具备200TOPS INT8/72TFLOPS FP16算力,并支持ChatGPT、LLaMA、Stable Diffusion等主流AIGC模型。其AIGC大模型一体机共使用8张VA1L加速卡,支持512GB显存,进而支持1750亿参数的大模型。VA12作为250W板卡,是VA1和VA10的升级版,有512TOPS INT8/160TFLOPS FP16算力,能够更高效地支持文生图模型Stable Diffusion。珠海芯动力发布首款基于可重构架构的GPGPU芯片RPP-R8。该公司在2017年成功研发出可重构并行处理器(RPP)架构,能够对AI推理的性能进行深度优化。以RPP架构为基础、面向边缘市场设计的第一代芯片RPP-R8已经一次性流片成功,芯动力成为GPGPU领域的新成员。
▲芯动力“六边形战士”处理器RPP
据悉,RPP-R8芯片是一款通用型GP-GPU芯片,每颗芯片内含有1024个计算核,相比传统GPU架构在同样的算力占用更小的芯片面积,实现了低功耗和高能效的有效平衡。RPP-R8除了具备专用芯片所没有的通用编程性,面积效率比可达到同类产品的7~10倍,能效比也超过3倍,可满足高效并行计算及AI计算应用。▲珠海芯动力RPP-R8芯片
其它参展芯片中,天数智芯2018年设计的天垓100加速卡目前已经跑通清华ChatGLM、LLaMA、智源研究院Aquila等大模型。今年6月,天数智芯宣布天垓100率先完成百亿级参数大模型训练。昆仑芯2代AI芯片是国内首款采用GDDR6显存的通用AI芯片,已经在金融、工业、交通、教育等领域广泛部署。昆仑芯在软件层面提供了丰富的云原生插件,帮助用户快速完成和大模型平台的适配。其产品矩阵适配文心一言、ChatGLM、GPT、OPT等主流行业大模型,并提供丰富的软件SDK,帮助用户快速完成适配和实时自定义的开发。海飞科称其第一代通用GPU芯片Compass C10是业界首个显存高达128GB的GPU芯片,达到了算力和存储容量的优化平衡,实现单卡、多卡分布式部署千亿大模型。海飞科展台演示有在其产品上跑Stable Diffusion、ChatGLM OPT等模型。
▲海飞科Compass C10计算卡
沐曦展示了其AI推理GPU曦思系列、通用计算GPU曦云系列、图形处理GPU曦彩系列芯片。其中,曦思N100是沐曦面向人工智能推理场景推出的一款高效能GPU产品,单卡算力达160TOPS (INT8)和80TFLOPS (FP16),已实现规模量产,并与多家重点客户及合作伙伴共同打造应用解决方案和生态联盟。▲曦思MXN100芯片
曦云C500是沐曦面向AI训练及通用计算的旗舰产品,提供强大高精度及多精度混合算力,配备大规格高带宽显存,片间互联MetaXLink无缝链接多GPU系统,能满足大模型推理和训练需求。曦云MXC500芯片已于2023年6月13日完成基础测试,预计将于今年年底实现量产。
▲曦云MXC500芯片
墨芯Antoum芯片是全球唯一拥有高稀疏率的AI芯片,采用12nm制程。凭借软硬协同的稀疏计算技术,搭载Antoum芯片的墨芯AI计算卡在权威AI基准测试MLPerf今年4月公布的结果中取得ResNet-50单卡、多卡的性能第一。墨芯AI计算平台可支持BLOOM、OPT、GPT-J、LLaMA、Stable Diffusion等主流大模型。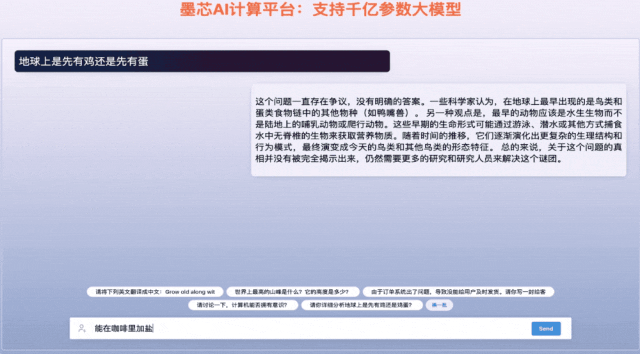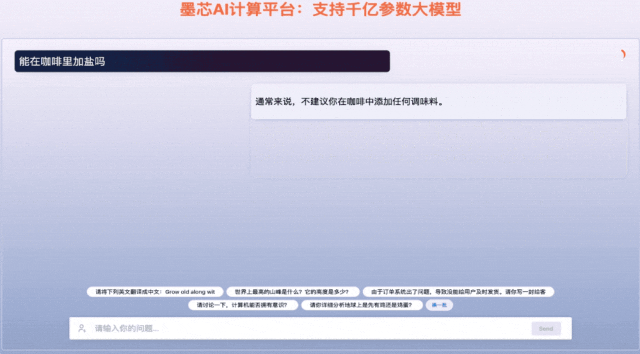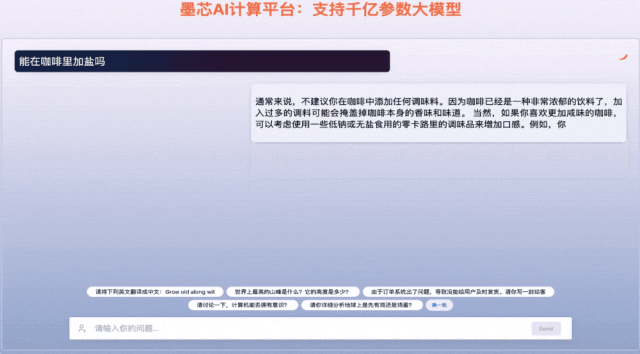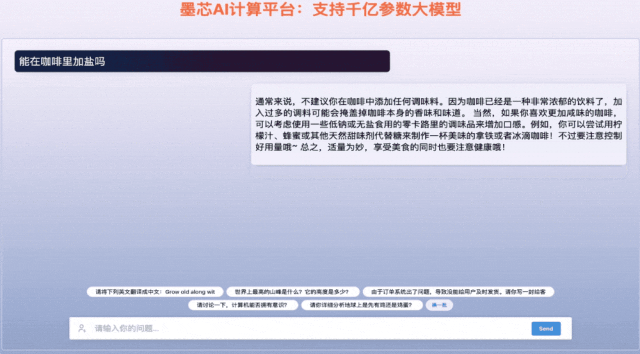
▲墨芯AI计算平台
英国AI芯片独角兽Graphcore(拟未)展出了入围SAIL奖TOP30榜单的云端高端推训一体加速卡C600,以及世界首款3D Wafer-on-Wafer处理器Bow IPU和基于4个Bow IPU构建的Bow-2000。Bow-2000可提供高达1.4PFLOPS的AI计算能力,并实现显著的电源效率提升。其C600 IPU处理器PCIe卡在此基础上增加了用于低精度和混合精度AI的FP8,主打推理,兼做训练,在搜索和推荐等业务上更具优势。Graphcore在支持大模型方面一直很积极,目前已部署在其IPU上的包括ChatGLM-6B、GPT2-XL、GPT-J、Stable Diffusion、Dolly 2.0等。Graphcore现场演示了在其IPU上运行中英双语模型ChatGLM-6B和开源文生图模型Stable Diffusion。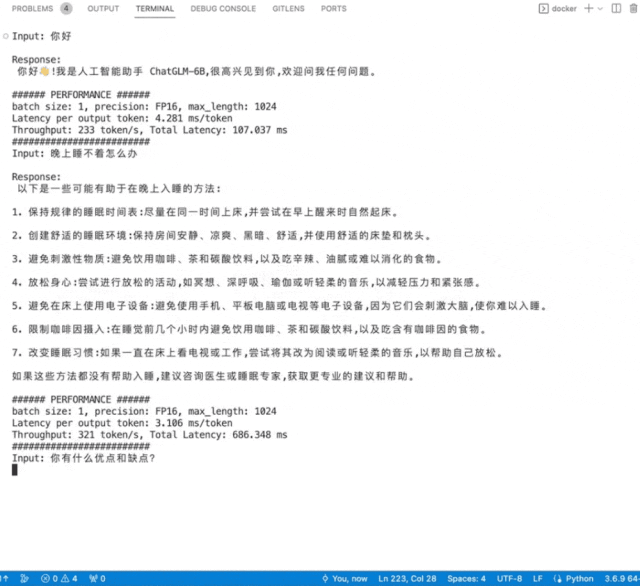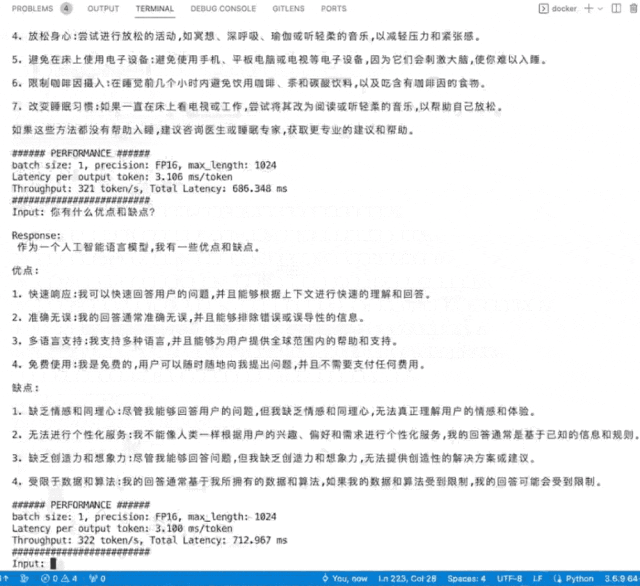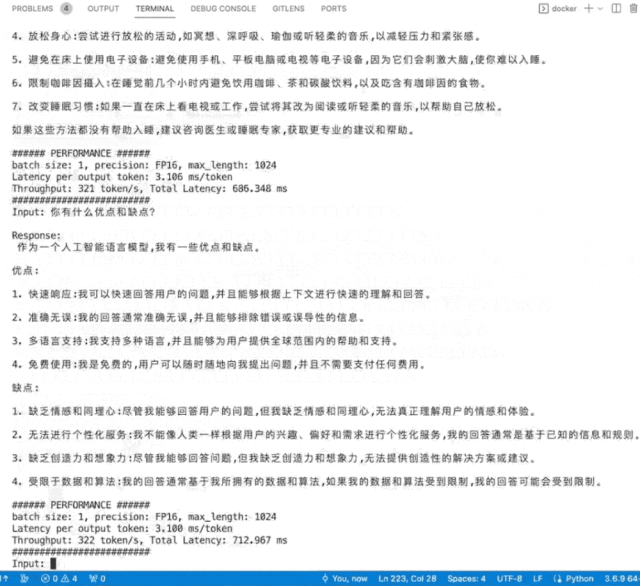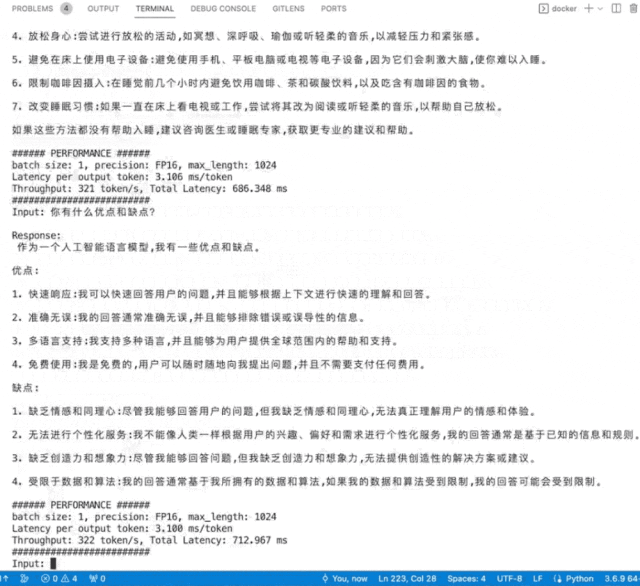
▲ChatGLM-6B模型在IPU上运行秒出多行回复
算能展出了第四代边云大算力AI芯片算丰BM1684X,以及首款基于RISC-V指令集架构的64核服务器CPU芯片算丰SG2042。每台基于SG2042的服务器会配置1张万兆光纤网卡,并根据硬盘配置选配RAID卡,使整个系统的操作起来与x86系统一样方便。
▲算丰RISC-V SG2042服务器简介
聚焦于计算+感知应用的爱芯元智,在WAIC上重点展示了第三代高算力、高能效比SoC芯片AX650N和M55、M76系列智能驾驶芯片。AX650N现已适配ViT/DeiT、Swin/SwinV2、DETR等Transformer模型,在DINOv2达到30帧以上的运行结果。Transformer网络SwinT在AX650N平台上实现了361FPS的高性能、80.45%的高精度、199FPS/W的低功耗以及原版模型且PTQ量化的极易部署能力。
▲爱芯元智边、端侧Transformer大模型展台
▲天数智芯大模型能力
燧原科技7月5日刚推出的新品燧原曜图(Enflame LumiCanvas)文生图MaaS平台服务产品在展会现场受到很多关注。这是燧原继3月宣布升级企业战略“以全栈软硬件和集群产品为数字底座,结合MaaS的业务模式,全面打造AIGC时代的基础设施”后的首款新品。这也是燧原在AIGC战略布局的第一步,后续燧原还将继续推出其它MaaS服务。
▲燧原曜图文生图MaaS平台服务产品
燧原曜图以燧原科技邃思系列芯片为算力支撑,由首都在线提供计算服务,集成了图像预处理、姿态建模、外部模型一键导入等能力,能够大批量生成图像,通过软硬一体方案降低大规模AIGC应用的工程难度与算力成本。这个企业级文生图应用支持以Excel形式批量导入prompt,单次最高可支持千条prompt导入,并针对视觉创作领域专业术语海量且繁复的问题,为用户提供prompt词典、大师经典作品prompt模板沉淀、逆向prompt等在内的全面Prompt工具体系。除了燧原曜图外,燧原还展出了有多个可交互设施的AIGC交互演示体验区,包括ChatBCG(文生PPT)、LLaMA(聊天机器人)、由清华ChatGLM和Stable Diffusion组成的能回复文字和图片的ChatBot(聊天机器人)等。
▲燧原AIGC交互演示展区
墨芯人工智能在WAIC期间发布了大模型算力方案的最新成果,展示1760亿参数的大语言模型BLOOM在墨芯AI计算平台的推理引擎支持下,能够快速、流畅地回答各类问题,并完成诗歌创作、文案撰写等多项语言生成任务。在1300亿参数ChatGLM大模型上,8张墨芯S30计算卡吞吐达432token/s,性能超过主流GPU。天数智芯亦展出了丰富的应用演示,包括大模型微调、大模型推理、代码生成、AI绘画、内容审查、虚拟数字人、隐私计算、风电场巡检、智慧语义、人脸比对、智算中心、3D建模、科学计算、智能OCR、目标检测/缺陷检测、智慧零售等,充分展示了其GPU产品的通用性。
▲天数智芯合作伙伴
登临科技设置了大模型、创新应用、AIDC、创新硬件四大主题展区,和合作伙伴一起展出了数十种产品方案,包括大模型、步态识别、数字孪生、无人机、智慧金融、智慧电力、智慧能源、智慧园区、车路协同、智慧社区、智慧交通等,并展示了其生态朋友圈。▲登临瀚海生态合作伙伴
燧原科技也晒出了生态合作伙伴。
▲燧原科技生态合作伙伴
虽然昆仑芯并未在展台设置关于AIGC应用的互动演示,但百度文心大模型早已是昆仑芯的金字招牌。值得一提的是,百度并没有因为昆仑芯是自家孩子而排斥其他AI芯片企业。百度展台上有一张标注飞桨在WAIC上的硬件伙伴们展位的地图,爱芯元智、登临科技、沐曦、昆仑芯、海飞科、墨芯人工智能、算能、燧原科技、瀚博半导体、天数智芯、Graphcore均在其中。
▲百度飞桨和硬件伙伴在WAIC

▲后摩鸿途H30芯片
国内FPGA龙头复旦微电重点展示了基于自研FPAI(可重构人工智能)芯片的一站式AI解决方案。忆芯科技展出了企业级SSD芯片等多种解决方案。西安紫光国芯则展出了世界领先的嵌入式DRAM(SeDRAM)、高带宽高性能板卡解决方案HBX-G500等科技创新成果。目前,上海集聚了全国最多的智能芯片创新企业,近年已有30多款AI训练芯片、AI推理芯片、车载芯片点亮,这些积累为通用大模型发展和落地普及打下了算力基础。*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。

