应对AI落地狂潮,新一代算力基础设施正在蓄势。作者 | ZeR0编辑 | 漠影当一群嗜血的互联****资客、互联网大鳄开始争抢类ChatGPT应用的入场券时,芯片玩家已悄然稳坐ChatGPT的牌桌。AI训练芯片“一哥”英伟达被视作云计算资本支出重心转向人工智能(AI)的最大受益者,韩国政府也在ChatGPT热潮中加大AI芯片扶持力度。今年1月3日至今,英伟达股价已上涨49%,市值从3522亿美元增至5261亿美元(折合增长了约1.19万亿人民币);据彭博亿万富翁指数,英伟达CEO黄仁勋的财富同期增长了60亿美元。如此“躺赚”,难怪黄仁勋谈到ChatGPT时满面笑容,直夸其意义堪比“iPhone时刻”。据花旗集团预估,ChatGPT将可能促使英伟达相关产品一年内销售额达到30亿~110亿美元。韩国政府亦高调进场,计划拿出约6.4亿美元投资研发先进AI芯片的公司,并将在下个月发布七个采用韩国AI芯片的K-cloud项目通知。据韩媒报道,当前三星和互联网巨头Naver合作开发AI芯片的进展尤其受关注,Naver计划在今年上半年推出自己的对话式AI服务SearchGPT。韩国AI芯片创企FuriosaAI也宣布明年将推出一款“可用于运行ChatGPT的最强大芯片”,采用5nm、HBM3技术,带宽是前代AI芯片的30倍。随着生成式AI和大模型兴起,飙涨的算力需求成头号难题,能实现高算力高能效比的Chiplet、CPO(共封装光学)概念也被带火,涨幅居前。一场围绕AI算力的争夺战,正日益硝烟弥漫。本文福利:ChatGPT背后的支撑为人工智能大模型,在大模型的框架下,每一代GPT模型的参数量均高速扩张,ChatGPT的快速渗透、落地应用,也将大幅提振算力需求。推荐精品报告《ChatGPT对GPU算力的需求测算与相关分析》,可在公众号聊天栏回复关键词【芯东西295】获取。
01.训练ChatGPT聊聊天算力需求有多大?
ChatGPT爆火后,不仅多家国内外科技大厂加大对生成式AI的投资,原美团“二号人物”王慧文、出门问问创始人李志飞等科技大佬也满腔热血躬身入局,要做中国的OpenAI(研发出ChatGPT和GPT-3的AI公司)。另据36氪向前搜狗CEO王小川本人求证是否回归创业做AI大模型的消息,王小川承认自己在“快速筹备中”。战场正变得越来越热闹,但回归理性,研发AI大模型可不是谁都能做的。此前海通证券分析师郑宏达曾隔空吐槽,说5000万美元够干什么?大模型训练一次就花500万美元,训练10次?比照OpenAI这个模板,GPT-3大模型的单次训练成本上百万美元、总训练成本上千万美元。2022年,OpenAI总共花掉超过5.44亿美元,但收入只有3600万美元,年亏损超过5亿美元。没钱,没人才,没数据和算力,就根本拿不到参赛的入场券。人才是OpenAI能够睥睨一众竞争对手的本钱。OpenAI现有375名正式员工,其中大部分都是顶级AI研发大牛,需用高额薪酬来留住这些人才。除此之外,其最烧钱的当属计算和数据。据美国《财富》杂志披露,OpenAI一年的计算和数据支出高达4.1645亿美元,员工支出8931万美元,其他非特定营业费用为3875万美元。ChatGPT类产品的开发成本有多高呢?据外媒报道,分析师称ChatGPT Beta版本使用了10000个英伟达GPU训练模型,新一代GPT-5大模型正在25000个英伟达GPU上训练。ChatGPT是基于大模型GPT-3.5训练出的对话式AI模型。GPT-3.5跟前代GPT-3一样有1750亿个参数。GPT-3训练所需算力达3650PFLOPS-days,训练成本约140万美元。参数更多的大模型训练成本则介于200万~1200万美元之间。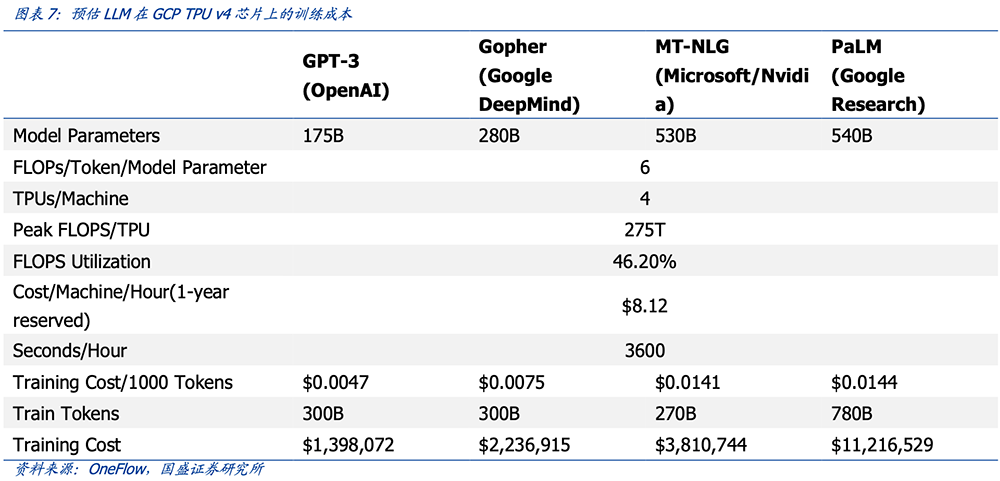
▲GPT-3、Gopher、MT-NLG、PaLM等大型语言模型的预估训练成本(来源:国盛证券)
据大算力AI芯片-存算一体专家陈巍测算,标准大小的ChatGPT-175B大概需要625台8卡DGX A100服务器进行训练,如果愿意等它跑1个月,200台8卡也够用。针对ChatGPT-175B的服务器成本(主要考虑GPU和CPU)约为3~5亿元。相对来说模型迭代成本没那么高。越往后迭代,大模型的训练成本可能会显著下降。自2020年5月GPT-3发布以来,与GPT-3性能相当的模型,训练和推理成本已经降低了超过80%。 
▲2020年对于具有对等性能的模型,与GPT-3相比,推理和训练成本降低的概览(图源:Sunyan)
而ChatGPT上线后的日常运营,又是一笔昂贵的算力开销。OpenAI CEO阿尔特曼曾在推特上回复马斯克的留言,说ChatGPT平均一次聊天成本是几美分。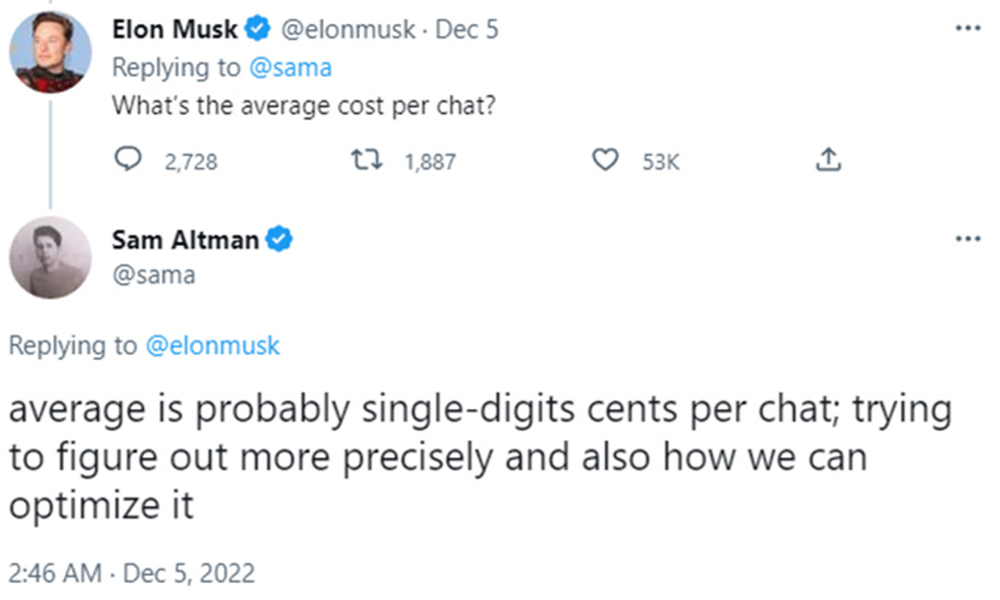
摩根士丹利分析称ChatGPT的一次回复可能会花掉OpenAI 2美分,大约是谷歌搜索查询平均成本的7倍。尤其考虑到ChatGPT面向全球大众用户,用的人越多,带宽消耗越大,服务器成本会更高。每天至少要烧掉10万美元。今年1月,ChatGPT累计用户数冲破1亿大关,访问量达6.72亿次。根据Similarweb数据,1月27日到2月3日,ChatGPT每日访客数达2500万。国盛证券估算,假设以这样的稳定状态,且忽略集群配置的请求量冗余和服务质量冗余,那么,ChatGPT需要至少30382片英伟达A100 GPU芯片同时计算,才能支撑当前ChatGPT的访问量;对应初始投入成本约为7.59亿美元(折合约52亿人民币);每日电费约为4.7万美元。另据招商通信测算,ChatGPT在模型上线运营阶段,每亿活跃用户将带来13.5EFLOPS的算力需求,需要6.9万台DGX A100 80G服务器支撑。按每个用户每天收到1500字回答计算,以2021年全球超算算力的总规模14EFLOPS,仅能支撑ChatGPT最多拥有1亿日均上线人数。微软、谷歌、百度等搜索巨头都计划将ChatGPT同类技术整合到它们的搜索引擎中。据SemiAnalysis估算,将这类技术集成到谷歌的每个搜索查询中,需要超过51万台A100 HGX服务器和总共超过410万个A100 GPU,服务器和网络总成本的资本支出将达到1000亿美元。这些支出的相当一部分,将流入英伟达的口袋。
▲中信证券认为短期内单个大模型可带来超过2万个A100的销售增量,对应市场规模超过2.13亿美元(图源:中信证券)
02.英伟达****不赔大算力AI芯片被带飞
那么,ChatGPT究竟要用到哪些计算基础设施?我们先来看看ChatGPT自己的回答:
可以明确的是,ChatGPT这股飓风刮得越猛,英伟达等大算力供应商就越吃香。过去五年,大模型发展直冲万亿参数,算力需求随之陡增。而ChatGPT幕后的算力功臣英伟达GPU,长期独占大多数AI训练芯片市场。摩尔线程摩尔学院院长李丰谈道,当前几乎所有的生成式AI算力都依赖GPU,尤其是在训练方面。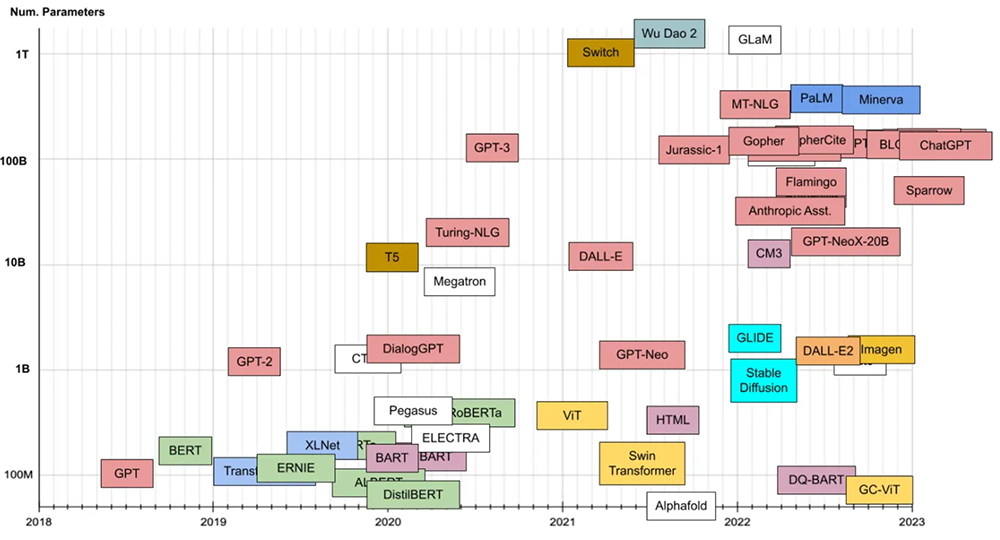
▲近年大模型的参数规模增长趋势(图源:Xavier Amatriain)
提高峰值吞吐量方面,英伟达一马当先。2018年,英伟达CEO黄仁勋曾提出“黄氏定律”,称GPU的增速是五年前的25倍。自2016年首次在V100 GPU中用上张量核心至今,英伟达通过各种创新设计不断抬高单芯片算力的天花板。作为全球AI计算头部企业,英伟达坐拥高度粘性的开发者生态,同时始终保持着敏锐的前瞻性布局,例如在H100 GPU使用Transformer引擎来显著提升大模型训练的速度,通过在GPU、CPU、DPU、AI、互连、网络等多方面的投资布局持续拉大在数据中心的竞争优势。据浙商证券分析,采购一片英伟达顶级GPU成本为8万元,支撑ChatGPT的算力基础设施至少需上万颗英伟达A100,高端芯片需求的快速增加会进一步拉高芯片均价。 同时,数据中心日益需要更加高性价比、高能效的AI芯片。据Sunyan估算,今天,用于训练大模型的数据中心GPU,代际每美元吞吐量提高了50%,代际每瓦特吞吐量提高了80%。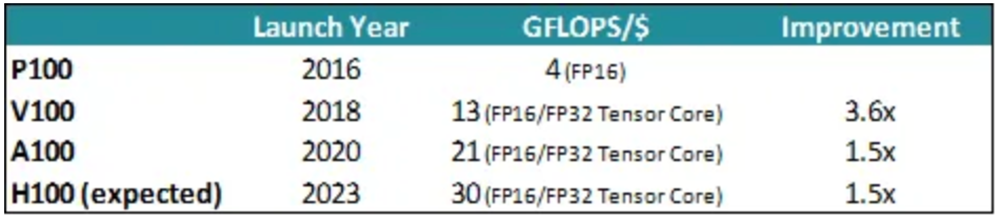
▲英伟达数据中心GPU FP16/FP32吞吐量/美元(图源:Sunyan)

▲英伟达数据中心GPU FP16/FP32吞吐量/瓦特(图源:Sunyan)
持续的芯片设计创新正推动了硬件成本和能效进一步优化。从基于训练GPT-3的V100到即将上市的H100的改进,预计可将内部训练成本从74.4万美元降至31.2万美元,降幅达到58%。
▲今天使用英伟达H100 GPU训练GPT-3的成本(图源:Sunyan)
再来看看ChatGPT对于是否会使用来自英伟达以外供应商的AI芯片的回复:
我们也问了ChatGPT关于其推理用到了哪些计算基础设施,这是ChatGPT给出的回答: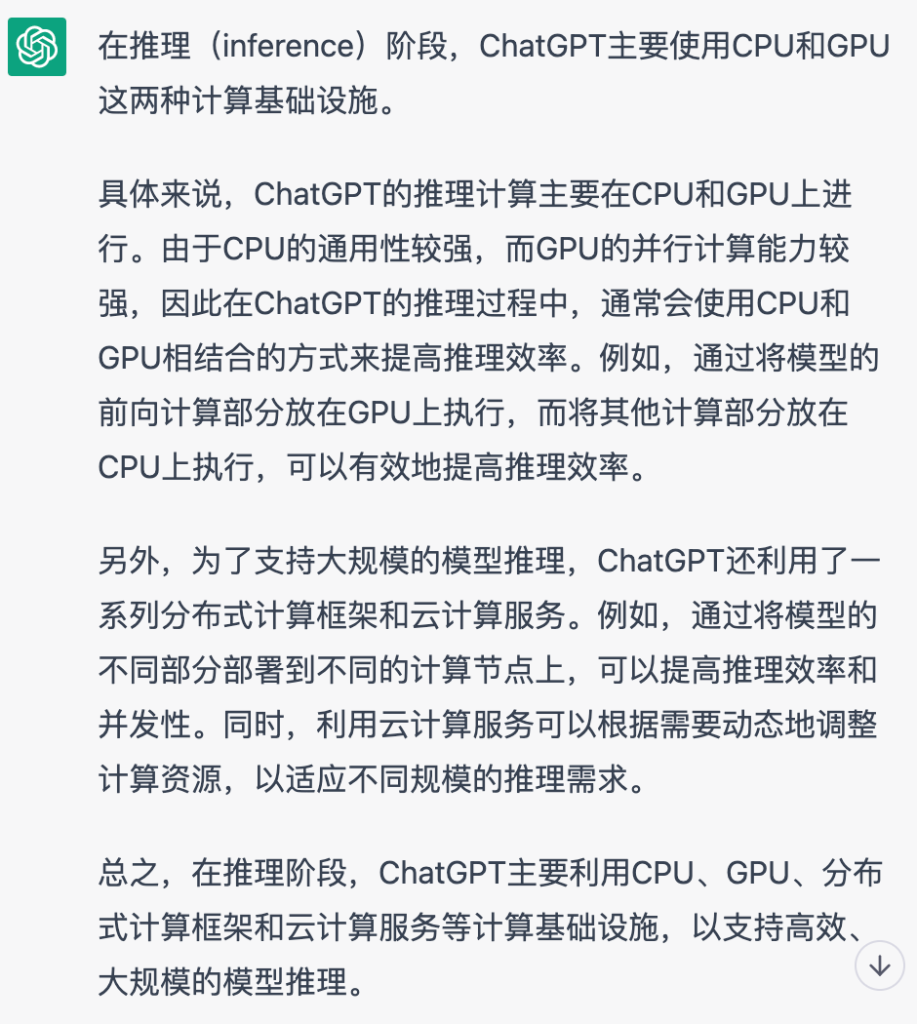
到目前为止,AI推理市场还是以CPU为主。但生成式AI模型的计算量对于CPU来说可能太大,需要GPU等加速计算芯片加以分担。总体来看,模型训练和终端用户流量飙增正拉动大算力需求,GPU、ASIC、DSA、FPGA、光子计算芯片、神经拟态芯片等各类加速计算芯片与通用芯片CPU的组合迎来更大的市场。不止是海外芯片巨头,国内AI芯片企业也感受到了ChatGPT带来的春意。燧原科技创始人兼COO张亚林认为,生成式AI大模型的出现,让国内的算力基础设施提供商能够更有针对性地提供与AI大模型强关联的基础设施,这对于国内创业公司在有限资源下聚焦、持续产品优化迭代提供了帮助。他告诉芯东西,燧原科技最近接到了很多客户和投资人的垂询,正全力推动产品的加速落地,去年其千卡规模液冷集群已经落地并服务战略客户群,能够全面支撑国内外生成式AI大模型。在他看来,相较于英伟达等国际大厂,国内AI芯片企业的优势可能体现在成本、特定市场及场景深度优化、本土化服务和支持等方面。通过与全栈大模型团队紧密合作,国内AI芯片团队能让客户问题的解决和产品迭代的飞轮更加快速。考虑到全功能GPU能更好地兼顾灵活度和应用开发,李丰认为将来的生态,会很长一段时间以GPU为主,辅以其他类型芯片的生态。
03.ChatGPT爆火后这些芯片技术迎来大风口
除了AI芯片外,高性能存储、Chiplet、互连技术、共封装光学(CPO)等概念近期均乘上了ChatGPT的高速列车。1、高性能存储芯片随着参数规模快速增长,大模型将增加扩展数据中心以稳定处理大量数据的需求。这将催化高性能存储芯片发展,例如高带宽内存(HBM)或内存内处理(PIM)的需求将因此增加。2018年推出的大模型BERT-Large拥有340M参数,仅需6.8GB内存,能轻松塞进单个桌面级GPU。而对于像GPT-3这样拥有1750亿个参数的模型,需要高达3.5TB的内存。英伟达H100的最大高带宽内存(HBM)容量也仅80GB,至少需要44个H100才能满足GPT-3的内存要求。 据韩国《经济日报》报道,受ChatGPT热潮驱动,三星电子、SK海力士两大存储芯片巨头的HBM接单量大增。三星还在去年10月与AMD合作开发了HBM-PIM技术,将存储芯片和AI芯片结合在一起,相比传统GPU能耗减半。2、Chiplet随着系统级芯片集成进入后摩尔时代,晶圆级芯片和基于Chiplet、存算一体等创新思路成为持续提高算力利用率的重要途径。其中,Chiplet作为“换道超车”的热门技术方案备受业界关注。不同于传统SoC设计方法,Chiplet将复杂芯片拆解成一组具有单独功能的Chiplet单元die,通过die-to-die的方式将模块芯片和底层基础芯片封装组合形成一个系统芯片,能够实现不同工艺节点的芯片产品搭配,降低芯片设计复杂度和设计成本,实现更高性能或具备更多功能的芯片。今年2月13日,首个由中国企业和专家主导制订的Chiplet技术标准《小芯片接口总线技术要求》正式发布实施。这是中国首个原生Chiplet技术标准,描述了小芯片接口总线技术的应用场景、体系结构、互连特性、信号管理等内容,适用于CPU、GPU、AI芯片、网络处理器和网络交换芯片等,对国内芯片产业突破先进制程工艺限制、绕过芯片制造良率瓶颈具有积极意义。标准文件链接:
https://www.ccita.net/wp-content/uploads/2023/02/TCESA-1248-2023-小芯片接口总线技术要求.pdf3、片上互连与片间互连单芯片撑不动后,大模型需要借助大规模分布式计算,将计算和存储任务拆分到更多的芯片中,因此芯片与芯片之间、系统与系统之间的数据传输效率愈发成为掣肘硬件利用率的瓶颈。无论是英伟达、英特尔、AMD等芯片大厂,还是Cerebras、Graphcore、SambaNova等海外AI芯片独角兽,都采用并支持分布式计算模型,并借助更快的内部互连技术将算力扩大。当传统基于铜互连的数据传输显得捉襟见肘,引入光网络的思路,可能有助于大幅提升芯片内、芯片间的数据传输效率。国内曦智科技正在做相关探索工作。(具体可参见《掀起数据中心算力新风口!大规模光电集成有多硬核?》)曦智科技创始人兼CEO沈亦晨告诉芯东西,高能效、低延迟的互连技术已经是潜在的技术壁垒。对此曦智科技提出使用片上光网络(oNOC)代替模块或板卡间的电互连,提高实现更高带宽、更低延迟,从而辅助Chiplet系统提高单芯片的算力和算效,为面向未来AI加速器的多形态计算架构提供关键的片上互连基础设施。4、共封装光学(CPO)由于ChatGPT需要大流量的云服务器支持,能显著提高通信效率、降低功耗成本的CPO(共封装光学)概念走红,相关概念股近期震荡走高。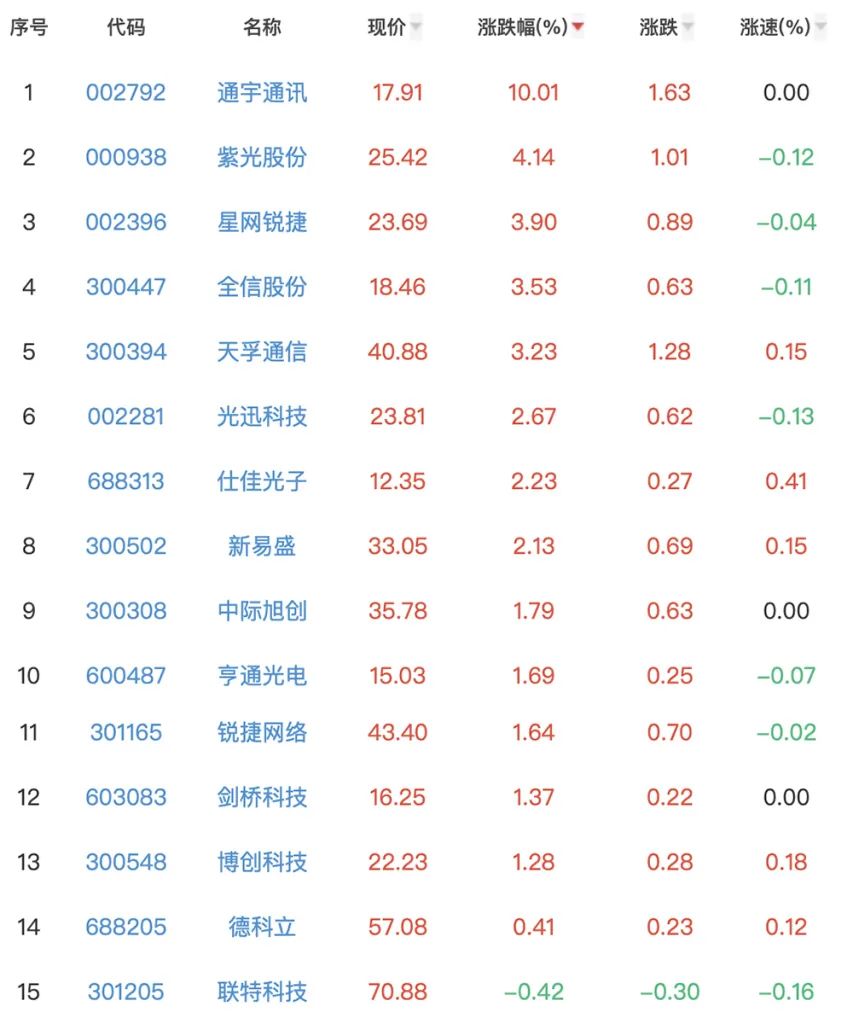
▲同花顺CPO概念股2月15日涨跌幅情况
CPO通过将硅光模块和CMOS芯片用高级封装的形式耦合在背板PCB上,缩短了交换芯片和光引擎间的距离,为暴涨的算力需求提供了一种小尺寸、高能效、低成本的高速互连解决方案。芯东西曾在《光互连最火概念!中国原生CPO标准草案来了,决胜数据中心未来》一文中梳理CPO技术发展的关键阶段和国内进展。中国计算机互连技术联盟(CCITA)秘书长郝沁汾告诉芯东西,CPO本质上是光模块结构发生了变化,给国内企业带来了重构光模块生态链和供应链的一个机会。当前《微电子芯片光互连接口技术》标准正在过工信部的技术审定会,这是国内唯一原生的CPO标准,也是世界三大CPO之一,后续中国计算机互连技术联盟将联合相关企业围绕该标准推进联合开发及技术验证。
04.结语
在即将到来的生成式AI驱动搜索时代,为AI构建下一代算力基础设施的竞争日趋激烈。从模型训练到日常运营,ChatGPT出生至今的每个环节都离不开几万片英伟达高端GPU的支撑。但英伟达GPU并非不可替代,此前一直有传闻,微软正在研发自己的AI芯片。如果生成式AI走向大规模商用,为了追求更极致的算力性价比,科技巨头将有足够的动力来设计专用芯片。除此之外,ChatGPT背后的AI公司OpenAI正在研发开源GPU编程语言Triton,希望打造一种比英伟达CUDA等特定供应商库更好用的软件,这可能会影响英伟达CUDA在开发者圈的需求。前路尚且充满未知,但许多计算芯片、存储芯片、网络基础设施供应商们已经严阵以待,准备好为新一轮AI狂潮蓄势。本文福利:ChatGPT背后的支撑为人工智能大模型,在大模型的框架下,每一代GPT模型的参数量均高速扩张,ChatGPT的快速渗透、落地应用,也将大幅提振算力需求。推荐精品报告《ChatGPT对GPU算力的需求测算与相关分析》,可在公众号聊天栏回复关键词【芯东西295】获取。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。
