英伟达江湖地位稳固,国产AI芯片新势力发起冲锋。作者 | ZeR0编辑 | 漠影AI芯片的战场,明显更热闹了。就在上周五,国际权威人工智能(AI)性能基准测试MLPerf公布了最新的数据中心及边缘场景AI推理榜单结果,无论是参与评选的企业还是实际AI芯片表现,都比往届多了不少看头。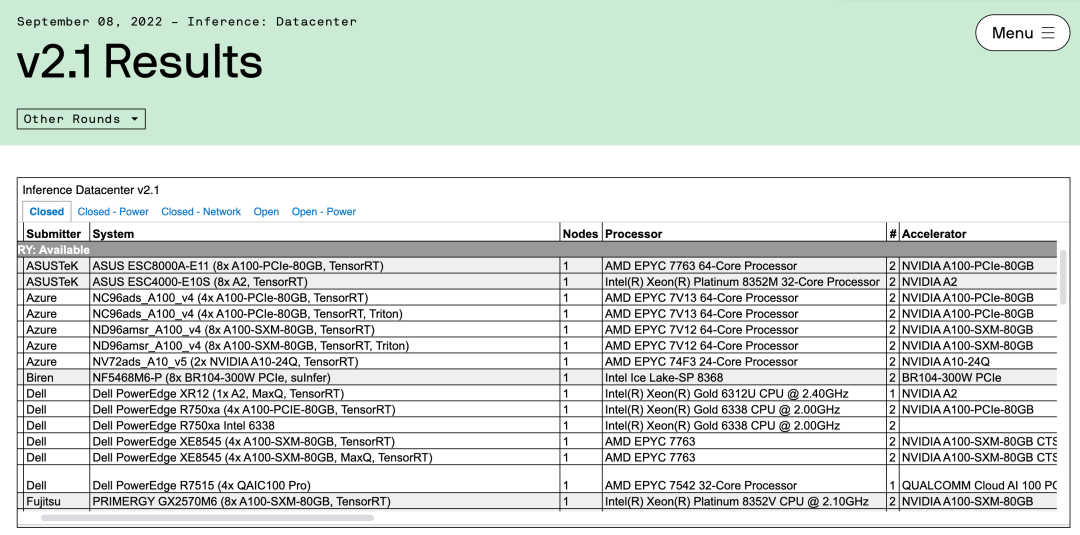
打头阵的自然还是国际AI计算巨头英伟达。这是英伟达(NVIDIA)第一次让其今年刚发布的最新旗舰AI加速器H100 Tensor Core GPU提交成绩,AI推理性能足足比上一代GPU高出4.5倍。高通则通过云端AI芯片Cloud AI 100的最新评测成绩,证明其在高能效方面依然很能打。国内AI芯片企业也不示弱,这次壁仞科技、墨芯人工智能均首次“参战”,并且战绩不俗,在部分模型的成绩甚至超过了英伟达旗舰AI芯片A100和H100。壁仞科技共提交了数据中心场景ResNet和BERT 99.90%精度两个模型的数据,同时包括Offline模式和Server模式,其离线模式8卡整机性能在BERT模型下达到英伟达8卡A100机型性能的1.58倍。墨芯的S30计算卡则在ResNet-50 95784 FPS的单卡算力夺得第一,达到英伟达H100的1.2倍、A100的2倍。还有韩国SK电讯在2020年11月推出的韩国首个AI芯片Sapeon X220,这次也通过参与测试展现出超过英伟达入门级AI加速卡A2性能的表现。不过,在今年6月训练基准测试榜单中大秀高性能、高能效成绩的谷歌TPU v4芯片,并没有出现在此次推理榜单中。此外,英特尔、阿里也分别展示了仅基于其服务器CPU的系统在加速AI推理方面的性能表现。总的来说,英伟达A100依然是横扫各大测试成绩的全能选手,还未上市的H100此次只是初露锋芒,预计训练性能的提升会更加“夸张”。国产AI芯片虽然只参加了ResNet、BERT等部分AI模型的评测,但单点战绩已经能与英伟达旗舰计算产品比肩,展现出在跑特定模型时替代国际先进产品的能力。MLPerf数据中心推理榜单:
https://mlcommons.org/en/inference-datacenter-21/
MLPerf边缘推理榜单:
https://mlcommons.org/en/inference-edge-21/
01.H100王者登场,英伟达仍然称雄
MLPerf基准测试按部署方式分为数据中心、边缘、移动、物联网四类场景,覆盖六类最具代表性的主流AI模型——图像分类(ResNet50)、自然语言处理(BERT)、语音识别(RNN-T)、目标物体检测(RetinaNet)、医学影像分割(3D-UNet)、智能推荐(DLRM)。其中,自然语言理解、医学影像分割和智能推荐3个任务设置了99%与99.9%两种精度要求,以考察提升AI推理精度要求对计算性能的影响。截至目前,英伟达是唯一一家在每轮MLPerf基准测试都参与所有主流算法测试的公司。英伟达A100在最新MLPerf AI推理测试榜单中依然大杀四方,在多类模型榜单的性能表现均名列前茅。A100的继任者H100首次在MLPerf亮相,连破多项世界记录,其性能比A100高出4.5倍。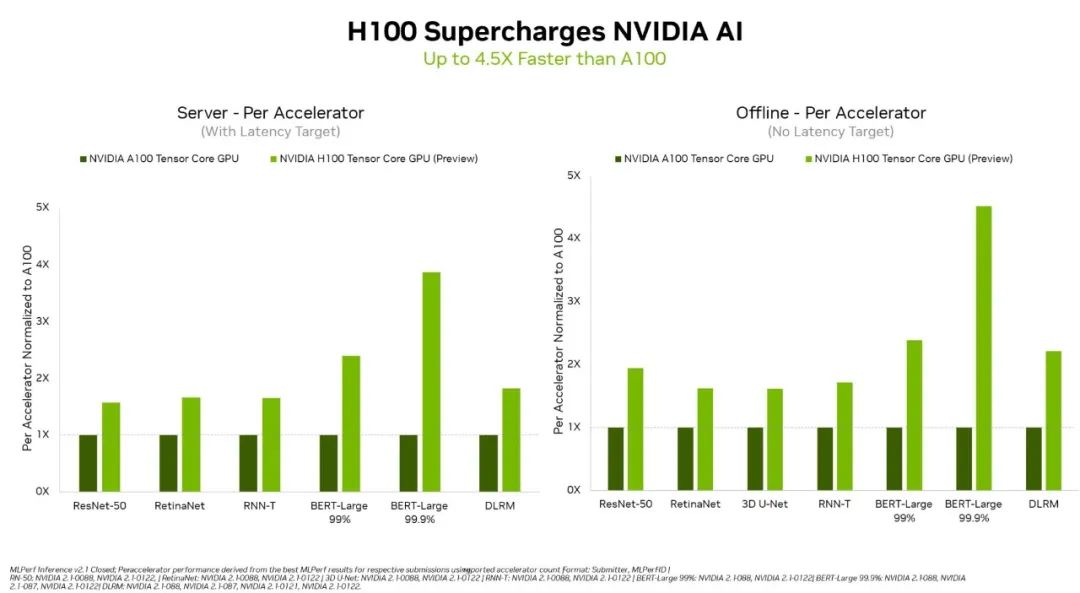
▲英伟达H100性能比A100高出4.5倍(图源:英伟达)
英伟达基于H100 GPU单芯片提交了两个系统,一个系统配备AMD EPYC CPU作为主机处理器,另一个系统配备英特尔至强CPU。可以看到,虽然采用英伟达最新Hopper架构的H100 GPU这次只展示了单芯片的测试成绩,其性能已经在多个情况下超过有2、4、8颗A100芯片的系统的性能。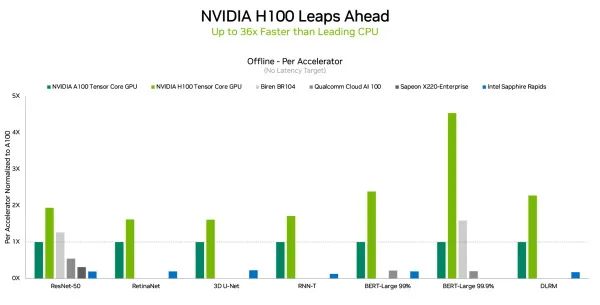
▲英伟达H100在数据中心场景所有工作负载都刷新性能记录(图源:英伟达)
特别是用在对更大规模、更高性能提出要求的自然语言处理BERT-Large模型上,H100的性能比A100和壁仞科技GPU超出一大截,这主要归功于其Transformer Engine。H100 GPU预计在今年年底发布,后续还会参加MLPerf的训练基准测试。此外,在边缘计算方面,将英伟达Ampere架构和Arm CPU内核集成在一块芯片的英伟达Orin,运行了所有MLPerf基准测试,是所有低功耗系统级芯片中赢得测试最多的芯片。值得一提的是,相比今年4月在MLPerf上首次亮相的成绩,英伟达Orin芯片的边缘AI推理能效进一步提高了50%。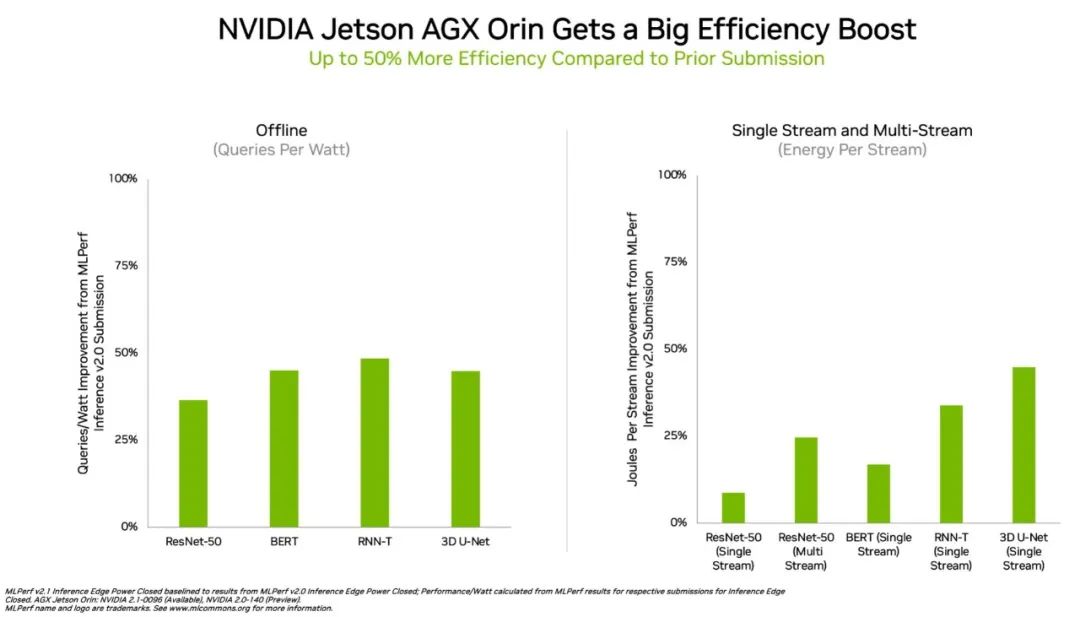
▲在能效方面,Orin边缘AI推理性能提升多达50%(图源:英伟达)
从英伟达往届在MLPerf提交的测试结果,可以看出AI软件带来的性能提升越来越显著。自2020年7月在MLPerf上首次亮相以来,得益于NVIDIA AI软件的不断改进,A100的性能已经提升6倍。目前,NVIDIA AI是唯一能在数据中心和边缘计算中运行所有MLPerf推理工作负载和场景的平台。通过软硬协同优化,英伟达GPU在数据中心及边缘计算中实现AI推理加速的成绩更加突出。
02.壁仞科技通用GPU参战ResNet和BERT模型性能超A100
壁仞科技今年8月刚发布的通用GPU芯片BR104,亦在MLPerf首次公开亮相。MLPerf推理榜单分为Closed(固定任务)和Open(开放优化)两类,固定任务主要考察参测厂商的硬件系统和软件优化的能力,开放优化则着重考察参测厂商的AI技术创新力。此次壁仞科技参加的是数据中心场景的固定任务评测,参评机型是搭载8张壁砺104-300W板卡的浪潮NF5468M6服务器,壁砺104板卡内置BR104芯片。壁仞科技提交了ResNet和BERT 99.9%精度模型的评测,同时包括Offline模式和Server模式。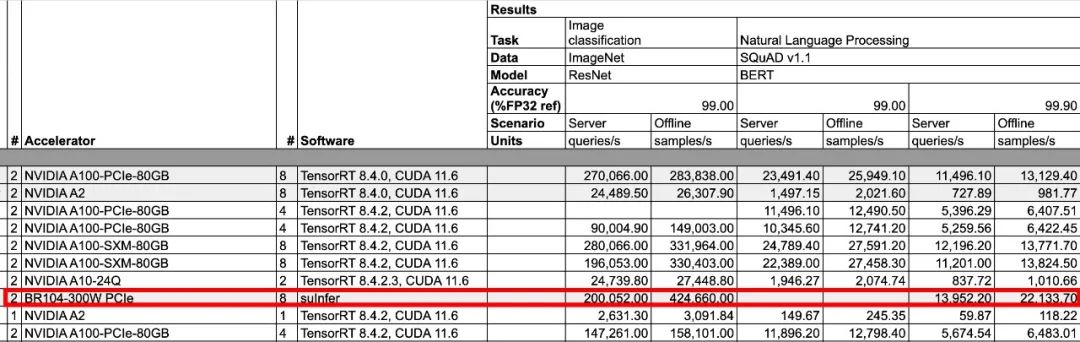
Offline模式对应数据在本地可用的情况,比如在ResNet-50、BERT模型中,Offline模式更为重要;Server模式的数据则来自即时数据,数据以突发和间歇的方式在线送达,比如在DLRM中,Server模式更重要。据悉,壁仞科技这次只选择这两类模型参评,主要考虑到两者是目前壁仞科技的目标客户应用最广泛、最重要的模型,特别是BERT模型。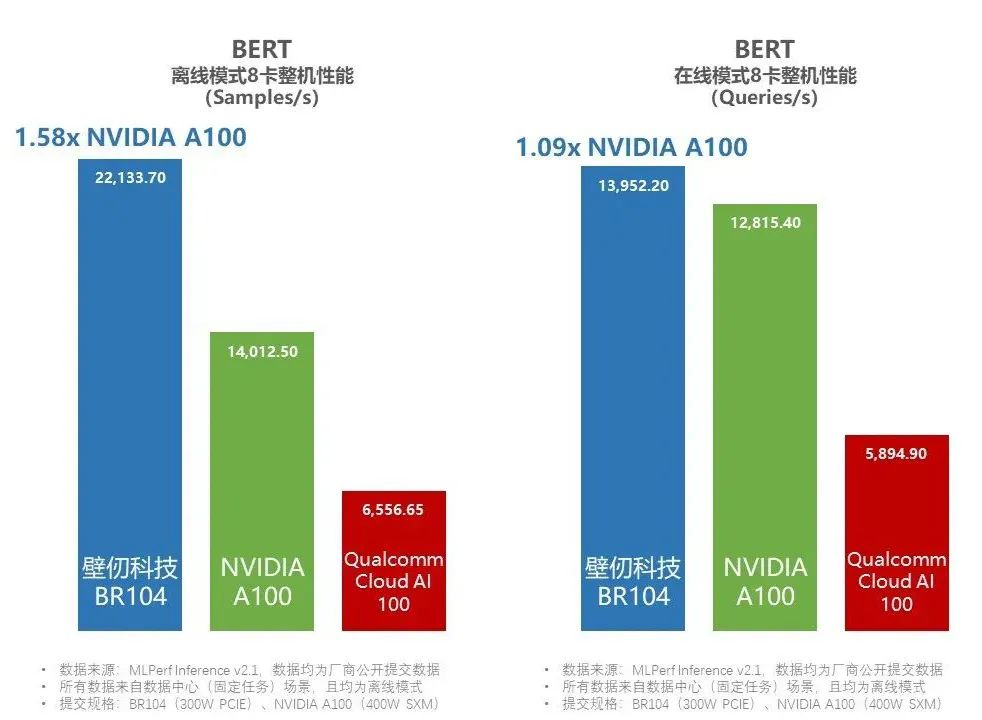
▲壁仞科技BR104在BERT模型评选中同时拿下离线和在线模式的整机性能领先(图源:壁仞科技)
从测试结果来看,在BERT模型的评选中,相较于英伟达提交的基于8张A100的机型,基于8张壁仞科技BR104的机型,性能达到了前者的1.58倍。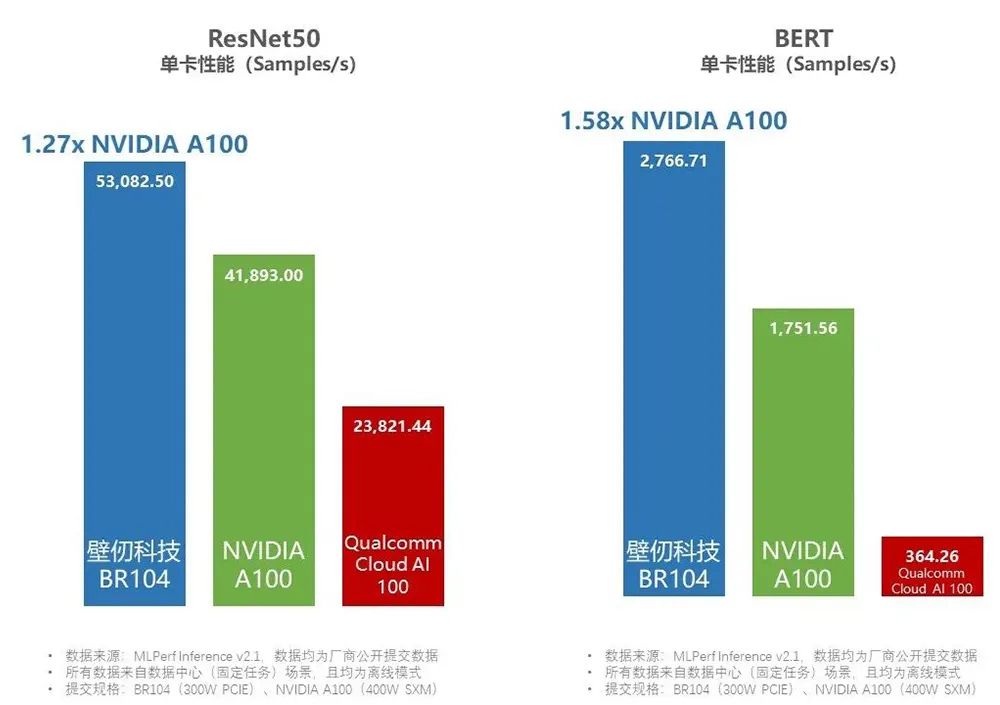
▲壁仞BR104在ResNet-50和BERT模型评选中单卡性能超过A100
总体来看,壁仞科技8卡PCle解决方案的性能表现,估计会介乎英伟达8卡A100与8卡H100之间。除了壁仞科技自己提交的8卡机型外,知名服务器提供商浪潮信息还提交了一款搭载4张壁砺104板卡的服务器,这也是浪潮信息首次提交基于国产厂商芯片的服务器测试成绩。在所有的4卡机型中,浪潮提交的服务器在ResNet50(Offline)和BERT(Offline & Server, 99.9%精度)两个模型下,也夺得了全球第一。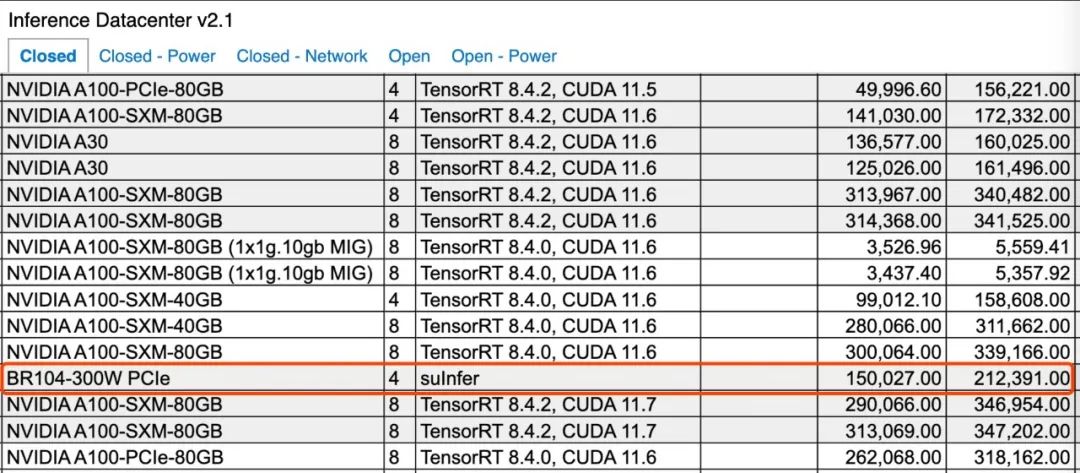
对于一家初出茅庐、首次推出芯片的初创公司来说,这个成绩已经非常惊人了。
03.墨芯S30夺魁图像分类单卡算力95784 FPS远超H100
另一家中国云端AI芯片企业墨芯人工智能同样首次参评MLPerf,而且在图像分类模型的推理任务上取得了超过英伟达H100的单卡算力表现。墨芯设计AI芯片英腾处理器(ANTOUM)时采用了自研双稀疏化技术来实现底层的芯片架构创新,从而兼顾数据中心对高性能和高能效比的需求。在今年的GTIC 2022全球AI芯片峰会上,墨芯人工智能首次向业内全面发布其首批面向数据中心AI推理应用的高稀疏率计算卡S4、S10和S30,分别为单****、双****和三****。
▲墨芯人工智能S30计算卡
此次墨芯参加的是开放优化类的测试。根据最新MLPerf推理榜单,墨芯S30计算卡以95784FPS的单卡算力,夺得ResNet-50模型算力第一,是H100的1.2倍、A100的2倍。在运行BERT-Large高精度模型(99.9%)方面,墨芯S30虽未战胜H100,却实现了高于A100性能2倍的成绩,S30单卡算力达3837SPS。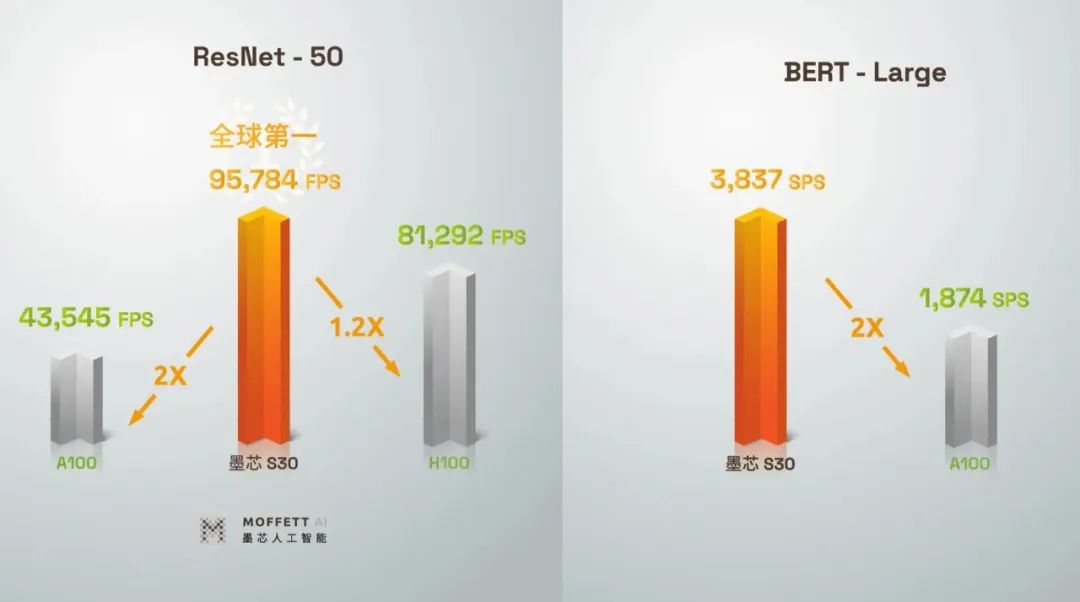
▲运行ResNet-50和BERT-Large模型时,墨芯S30与A100、H100的对比(图源:墨芯人工智能)
值得一提的是,墨芯S30采用的是12nm制程,而英伟达H100采用的是更先进的4nm制程,能够在制程工艺存在代际差的情况下追平两大数据中心主流AI模型的性能表现,主要得益于墨芯自主研发的稀疏化算法及架构。MLPerf的测试要求非常严格,不仅考验各产品算力,同时设置精度要求在99%以上,以考察AI推理精度的高要求对计算性能的影响,也就是说参赛厂商不能以牺牲精度的方式换取算力提升。这亦证明了墨芯能做到在实现稀疏化计算的同时兼顾精度无损。
04.高能效,高通云端AI芯片的王牌
高通早在2019年就发布的首款云端AI芯片Cloud AI 100,继续坚挺地参评MLPerf,与一众新AI加速器同场竞技。从测试成绩来看,单论在图像处理上的高能效,采用7nm制程的高通Cloud AI 100芯片依然可以笑傲江湖。
▲高通Cloud AI 100
MLPerf最新披露的评测结果中,富士康、创通联达(Thundercomm)、英业达(Inventec)、戴尔、HPE和联想都提交了使用高通Cloud AI 100芯片的测试成绩。可以看出,高通的AI芯片已经在被亚洲云服务器市场接纳。高通Cloud AI 100有两个版本,专业版(400 TOPS)或标准版(300 TOPS),都具有高能效的优势。在图像处理方面,该芯片的每瓦性能比标准部件的NVIDIA Jetson Orin高1倍,在自然语言处理BERT-99模型方面的能效亦是略胜一筹。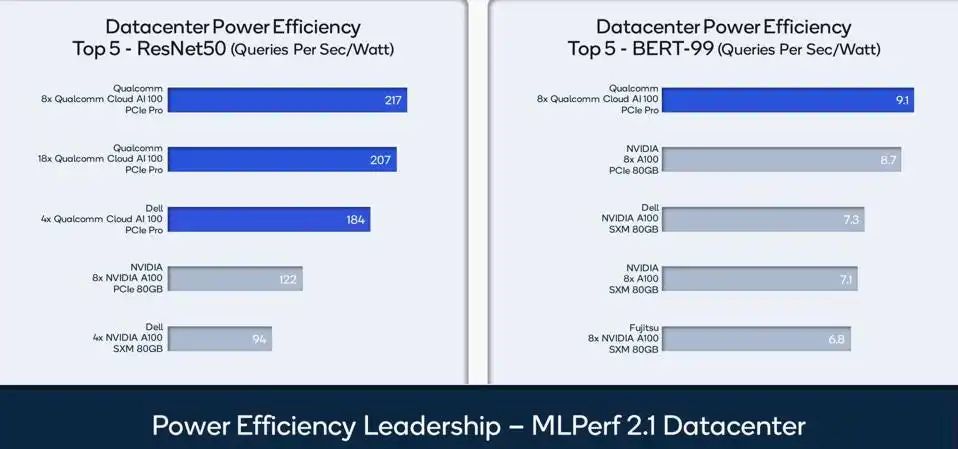
▲高通Cloud AI 100在ResNet-50及BERT-99模型测试中的能效比领先(图源:高通)
在保持高能效的同时,高通的AI芯片并没有以牺牲高性能为代价,一台5卡服务器功耗75W,可实现的性能比2卡A100服务器高出近50%。而单台2卡A100服务器的功耗高达300W。
▲高通Cloud AI 100的每瓦性能表现(图源:高通)
面向边缘计算,高通Cloud AI 100在图形处理方面展现出的高能效已经非常有竞争力,不过大型数据中心对芯片的通用性会有更高要求,如果高通想要进一步打入云端市场,可能得在下一代云边AI芯片的设计上扩展对推荐引擎等更多主流AI模型的支持。
▲实现边缘服务器高能效,不以牺牲高性能为代价(图源:高通)
05.韩国首款AI芯片亮相对打英伟达入门级AI加速卡
这次MLPerf榜单中,我们还看到了在AI芯片领域相对缺乏存在感的韩国企业的身影。Sapeon X220是韩国知名科技企业SK电讯自主研发的AI芯片,也是韩国第一颗用于数据中心的非存储类商用芯片,能够高速、低功耗地执行AI服务所需的大规模计算。
▲Sapeon X220部分参数
其测试结果也很有意思。Sapeon X220搭载于Supermicro服务器上,在数据中心推理基准测试中的性能超过了英伟达去年年底发布的入门级AI加速卡A2 GPU。其中,X220-Compact的性能比A2高2.3倍,X220-Enterprise的性能比A2提升4.6倍。能效表现同样不错,在基于最大功耗的每瓦性能方面,X220-Compact的能效是A2的2.2倍,X220-Enterprise的能效是A2的2.0倍。
▲Sapeon X220系列与英伟达A2的性能及能效对比(图源:SAPEON)
值得一提的是,英伟达A2采用的是先进的8nm制程,而Sapeon X220采用的是28nm成熟制程。据悉,Sapeon芯片已经应用在智能音箱、智能视频安全解决方案、基于AI的媒体质量优化解决方案等应用中。今年SK电讯还将AI芯片业务独立出来,成立了一家名为SAPEON的公司。SAPEON首席执行官Soojung Ryu透露说,未来该公司计划拓展X220的各个应用领域,有信心在明年下半年用下一代芯片X330与竞品拉开差距,进一步提高性能。
06.英特尔预览下一代服务器CPU阿里倚天710 CPU首参评
尽管云端AI推理芯片正呈百家争鸣之势,但截至目前,服务器CPU仍是AI推理市场的主导者。在此次MLPerf榜单中,我们看到仅搭载英特尔至强、阿里自研CPU倚天710的系统参评,这些系统没有搭载任何AI加速器,可以较真实的反映出这些服务器CPU的AI推理加速能力。在固定任务榜单中,英特尔提交了一个预览版Sapphire Rapids 2-socket搭配PyTorch软件的系统,推理性能虽被H100“虐杀”,但已经足够打败A2。毕竟这是一款服务器CPU,AI推理加速能力只是它的加分项,这样看来英特尔至强CPU的加速能力已经足够应对常规的AI推理任务需求。
在开放优化类榜单中,一家名为NeuralMagic的初创公司通过提交仅有英特尔至强CPU的系统,展示了其基于剪枝技术实现更精细的软件,用更少的算力就能实现与其他软件同等的性能。
阿里巴巴亦首次展示了整个集群作为单机运行的结果,在总吞吐量上超过其他结果。其自研倚天710 CPU芯片首次出现在MLPerf榜单中。
另外从各厂商参评这次MLPerf的系统配置,我们可以看到,AMD EPYC服务器CPU在数据中心推理应用中的存在感越来越高,大有与英特尔至强并驾齐驱的势头。
07.结语:英伟达江湖地位稳固国产AI芯片新势力发起冲锋
总的来看,英伟达继续稳定发挥,霸榜MLPerf推理基准测试,是毫无争议的大赢家。虽说部分单点性能成绩被其他竞品赶超,但若论通用性,英伟达A100和H100依然是能将其他一众AI芯片“按地摩擦”的存在。目前英伟达还没有提交H100的推理能效测试数据,以及其在训练方面的性能表现,等这些成绩出来,H100预计会风头更盛。国产AI芯片企业也崭露锋芒。继阿里平头哥自研云端AI芯片含光800的单卡算力在2019年登顶MLPerf ResNet-50模型推理测试后,壁仞科技、墨芯也分别通过第三方权威AI基准测试平台展示出其AI芯片的实测性能实力。从这次开放优化类榜单展示的性能成绩,我们看到稀疏性计算已经成数据中心AI推理的一个热门趋势,我们期待接下来这类具有创新力的技术能进入固定任务榜单,通过更精细、更公平地比较系统实力,进一步验证其落地价值。随着参评机构、系统规模、系统配置的增加和走向多元化,MLPerf基准测试正变得越来越复杂。这些历届的榜单结果,也能反映出全球AI芯片的技术及产业格局之变迁。芯东西芯东西专注报道芯片、半导体产业创新,尤其是以芯片设计创新引领的计算新革命和国产替代浪潮;我们是一群追“芯”人,带你一起遨游“芯”辰大海。
680篇原创内容
公众号
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


