三年磨一剑,团队规模已近千人。作者 | 心缘编辑 | 漠影芯东西8月9日报道,今日下午,上海GPU独角兽企业壁仞科技推出首款面向云端人工智能(AI)训练及推理的通用GPU算力产品BR100系列,其旗舰产品的峰值算力超过了英伟达目前在售的旗舰计算产品A100 GPU的3倍。
▲张文展示BR100芯片
“全球通用GPU算力纪录,第一次由一家中国企业创造。”在发布会上,壁仞科技创始人、董事长、CEO张文宣布,“中国通用GPU芯片进入每秒1,000,000,000,0000,000次计算新时代。”
壁仞科技成立于2019年9月9日,再过一个月,就是其三周年的纪念日。团队总共经过1065个日日夜夜的奋战,这才有了这款大算力芯片的诞生。在此之际,张文也宣布他的下一个小目标:“百年基业长青”。BR100芯片采用7nm制程、壁仞原创“壁立仞”芯片架构,容纳近800亿颗晶体管,配备超300MB片上高速SRAM,并应用Chiplet与2.5D CoWoS封装技术,突破了大尺寸芯片制造与封装中的光罩尺寸限制问题,做到高良率与高性能的兼顾。
它也是国内互连带宽创纪录芯片。BR100还首次引入了壁仞科技原创定义的TF32+数据精度,可提供比英伟达TF32更高的数据精度与吞吐性能。同时壁仞提供有配套的原创异构计算平台BIRENSUPA,提供端到端全栈覆盖。
此外,壁仞科技与浪潮现场共同发布了创全球性能纪录的OAM服务器“海玄”,其峰值浮点算力达8PFLOPS,最大功耗为7KW,并提供高能效、低TCO(总拥有成本)的数据中心集群方案。“我见过很多豪华的创业团队失败,但是从来没见过有信仰的团队失败。”张文分享说,自己的创业理念是“做难而正确的事,真正替社会创造价值”。目前,壁仞科技团队规模已超过900人,并有望在今年年底达到千人规模,其中85%以上拥有硕士及以上学位。除了通用GPU外,壁仞科技也启动了图形GPU产品线。围绕BR100芯片的更多技术细节和落地进展,芯东西采访了多位壁仞科技高层。壁仞科技联合创始人、总裁徐凌杰告诉芯东西,BR100系列芯片以及相应硬件计算产品将于今年年底量产。
01.全球最强性能通用GPU八大核心特性
壁仞科技BR100系列通用GPU算力产品针对AI训练、推理,以及更广泛的通用计算场景而设计,主要应用于数据中心部署场景,兼具高算力、高能效、高通用性等特点。 ▲壁仞BR100芯片与英伟达H100/A100基础规格对比
▲壁仞BR100芯片与英伟达H100/A100基础规格对比
综合来看,其旗舰产品BR100有8项核心特性:(1)先进制造及封装技术:采用7nm制程工艺,在1074mm²芯片面积上集成了770亿颗晶体管,并应用了前沿的Chiplet与2.5D CoWoS封装技术,能够兼顾高良率与高性能。(2)高性能及高能效比:核心性能媲美英伟达最新推出的旗舰计算产品H100 GPU,较英伟达A100算力提升3倍以上。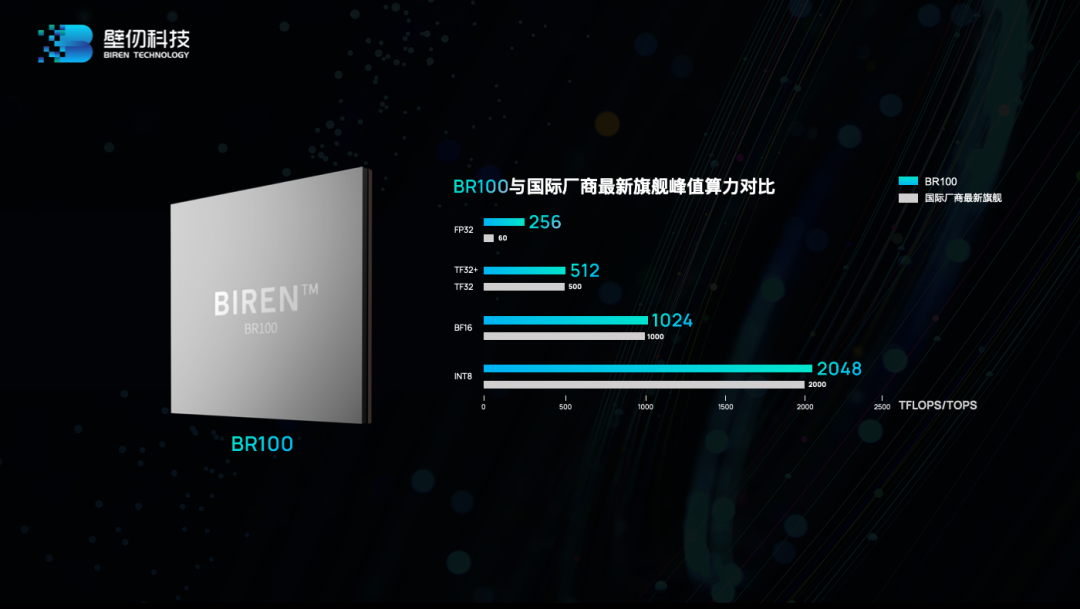
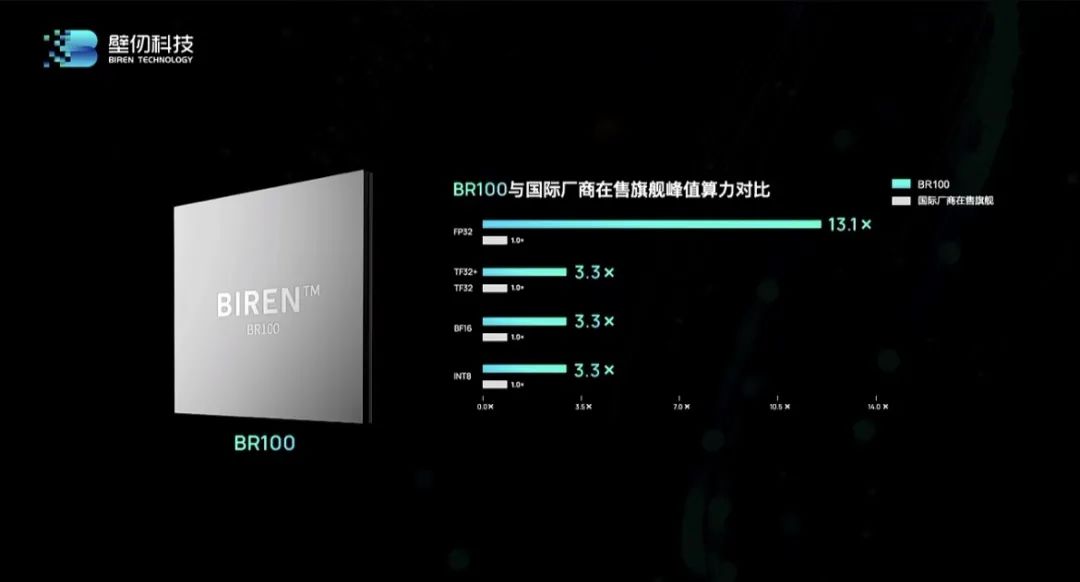
(3)多数据精度支持:除了原生支持FP32、BF16、FP16、INT8等主流数据精度外,还支持壁仞原创定义的TF32+数据精度。与TF32相比,TF32+在满足相同动态表示范围的前提下,增加了5位尾数(mantissa),可实现比TF32更高的数据精度与吞吐性能,适用于大量的乘加计算。
(4)先进内存系统:64GB HBM2e片外内存,数据速率高达3.2Gbps,带宽高达1.64TB/s,总计位宽4096bit。(5)先进互连系统: 原创BLink高速GPU互连技术,采用最新高速serDes技术,支持8卡点对点全互连,聚合带宽达512GB/s,创国内互连带宽纪录;采用最新一代主机接口PCIe 5.0并率先支持CXL 2.0通信协议,双向带宽高达128GB/s。
(6)安全虚拟实例(SVI):最高支持8个独立实例,每个实例物理隔离并配备独立的硬件资源,可独立运行。(7)国密安全规范:专用硬件加解密IP,支持 AES等常用安全加密算法,符合国密一级安全规范。(8)OCP规范硬件系统:符合OCP规范的OAM模组,最高支持550W TDP风冷散热,并在通用UBB主板上实现8卡点对点全互连。BR100系列还包含另一款主流级数据中心加速计算芯片BR104,可适配成熟、部署广泛的PCIe板卡形态。
BR104搭载于训推一体主流级产品壁砺104 PCIe板卡上,它采用标准PCIe形态,整卡峰值功耗300W,适配多种2-4U的PCIe GPU服务器,与现有基础设施高度兼容,现已开放邀测。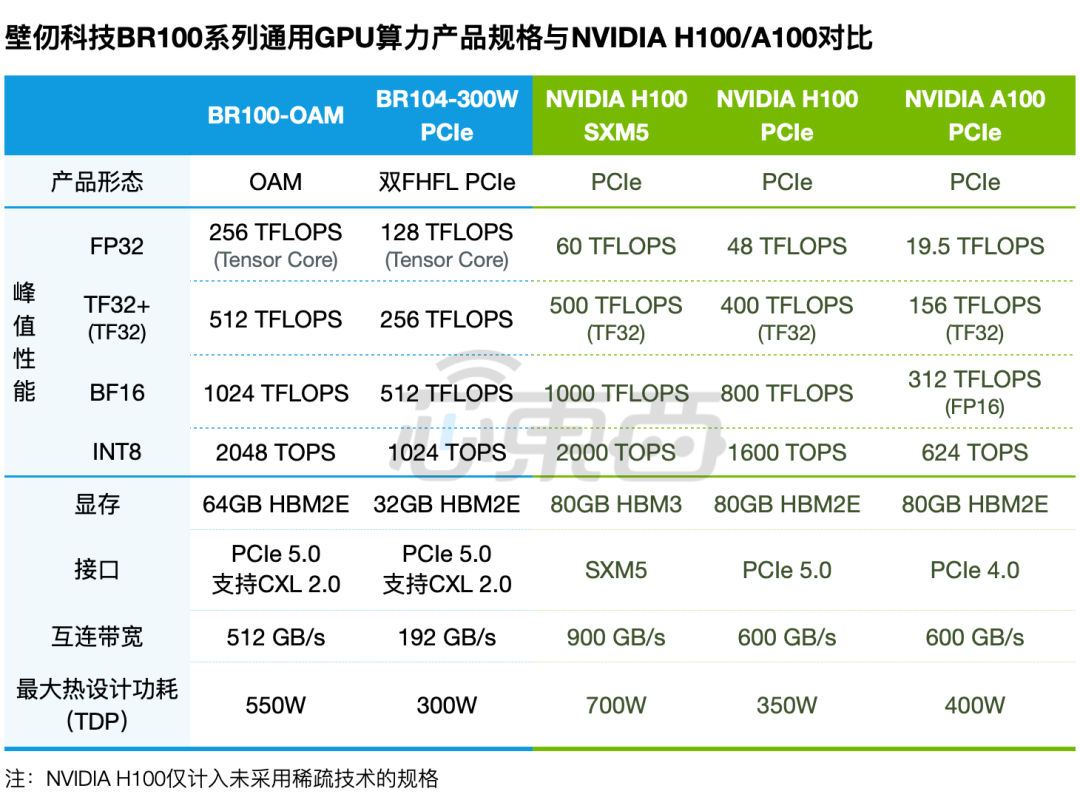
▲壁仞BR100系列产品与英伟达H100/A100规格对比
02.原创训推一体架构,自研异构计算平台
针对通用大算力GPU面临的内存墙、功耗墙、并行性、互连和指令集架构等挑战,壁仞科技原创设计了训推一体芯片架构“壁立仞”,并为其通用GPU打造了完备的BIRENSUPA软件开发平台。壁仞科技CTO洪洲负责主导其首款通用GPU芯片BR100的原创架构研发设计,他将在今年8月26日举行的GTIC 2022全球AI芯片峰会·高峰论坛上发表《大算力通用GPU赋能超大模型训练》主题演讲。据他介绍,壁仞团队在微架构上,以通用计算核的设计为中心,搭配强大的张量计算引擎,来进行加速计算;同时采用自研指令集,以更高效地实现各功能运行。

具体来看,BR100有32个SPC流式处理器簇,每个SPC有16个EU执行单元,每4个EU可配置成1个CU计算单元,每个SPC共4096个线程。而每个EU有16个通用流式处理器,同时包含采用脉动3D GEMM架构的专用张量引擎。

BR100总计拥有8192个通用流式处理器、512组专用张量加速引擎,共128K个线程,配备256MB分布式共享L2级缓存,支持多SPC间数据共享,并可配置成大容量的scratchpad,还能支持不同层次的近存储计算。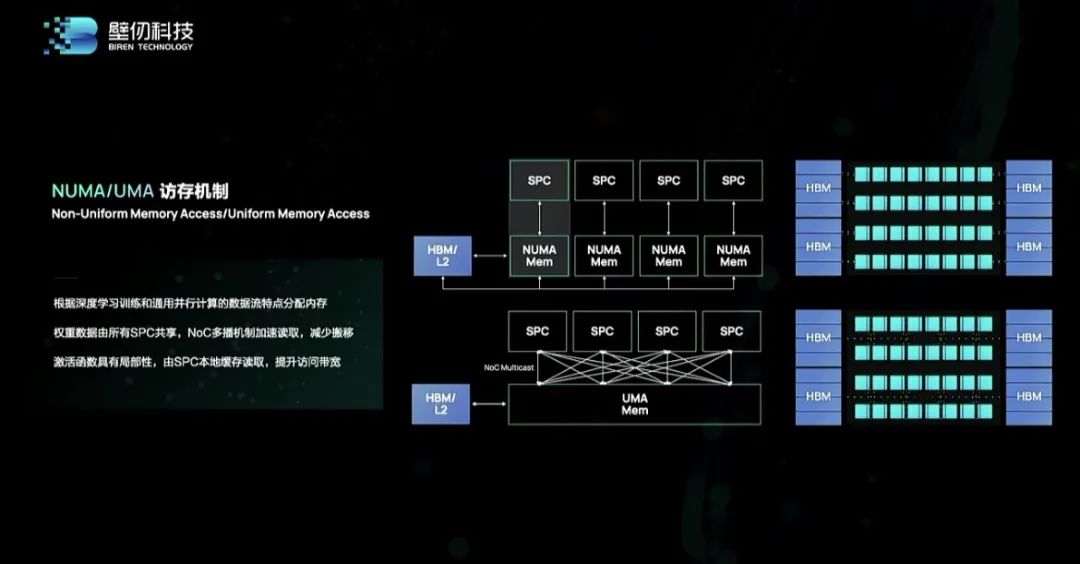
其自研的GPGPU架构及指令集搭配多级缓存架构,可实现大模型训练下的数据重用;基于NoC的通讯架构,支持共享数据多播机制,可以与分布式缓存配合实现高效通信,大大减少对片外带宽的需求,并大幅降低功耗。如前文所述,除了架构设计外,BR100还采用了许多业界领先的芯片技术,包括风头渐盛的chiplet。洪洲向芯东西解释说,对于可明确划分功能模块的芯片,或在公司产品线非常丰富、产品线之间可重复使用特定模块的情况下,采用自研chiplet方案进行SoC功能模块的复用可以缩短设计周期、降低设计成本并大幅提升良率。这要求芯片设计团队具备对高速接口、大芯片封装有丰富经验。

需注意的是,壁仞科技此次推出的通用GPU产品,主打面向云端数据中心场景的AI计算及通用科学计算,不能与图形GPU划等号。壁仞科技联席CEO李新荣告诉芯东西,为了强化计算能力,通用GPU往往会弱化图形渲染,并且往往没有显示输出接口,并不能直接用于游戏等应用(英伟达的专业计算卡虽也具备渲染能力,但也只能用于云端渲染)。这是由它的应用场景和设计特点所决定的。另外,有部分人士会认为专用AI芯片的能效比一定比通用GPU能效比高,可以取代通用GPU,但李新荣特别谈道,这一观点并不准确,因为不同芯片的能效比受架构、工艺等多种因素影响。即使某些专用芯片在特定场景下能效比高,也不一定能解决实际应用场景的大算力计算问题,尤其在训练场景下,GPU芯片的绝对算力大、通用性强、软件栈的易用性和丰富的软件生态等特点使得它仍然占据数据中心的加速计算主导地位。
“在数据中心场景下,所谓的专用AI芯片要取代GPU已经证明是非常困难的。”李新荣说。
与BR100系列芯片搭配,壁仞科技还自研了异构计算平台BIRENSUPA及配套软件开发工具,支持业内主流的深度学习框架与模型,从而为数据中心场景用户提供灵活、安全的算力部署,有效降低数据中心的总拥有成本。
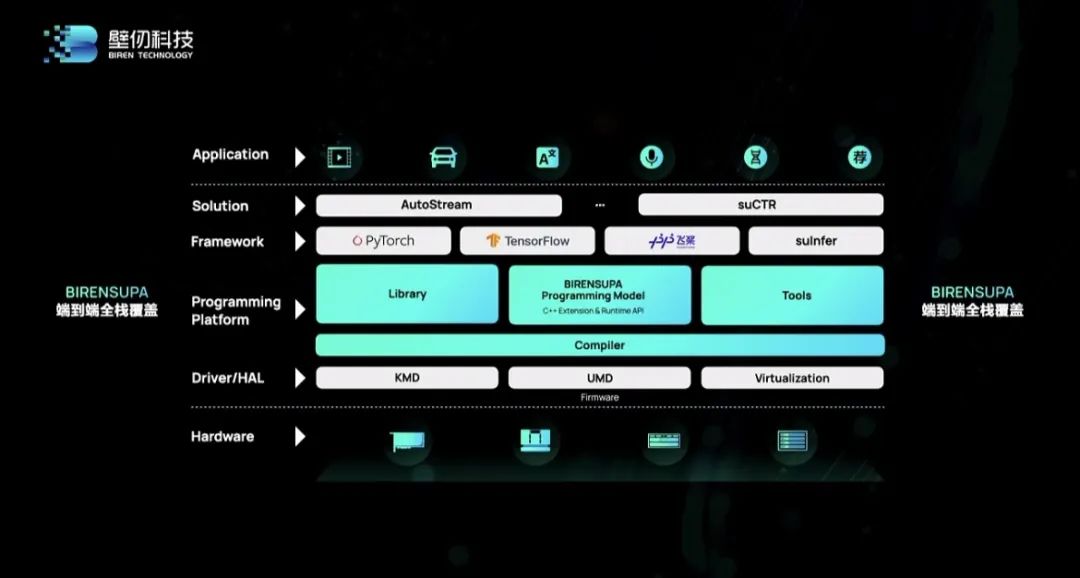
BIRENSUPA(BIREN Scalable Unified Parallel Architecture)平台是壁仞科技硬件设备上开发深度学习和通用计算应用的编程模型和软件平台,为应用程序提供轻松访问高性能并行处理硬件的能力,具备可开源、可扩展的特征。其完整软件栈包括固件、驱动程序、编译器、工具、编程模型、库、机器学习(ML)框架和端到端应用SDK,兼容TensorFlow、PyTorch、飞桨等主流深度学习框架。BIRENSUPA还支持壁仞自研高性能推理引擎并适配第三方推理引擎,支持现有GPU代码平滑迁移。
03.已与重点客户启动产品适配进入测试阶段
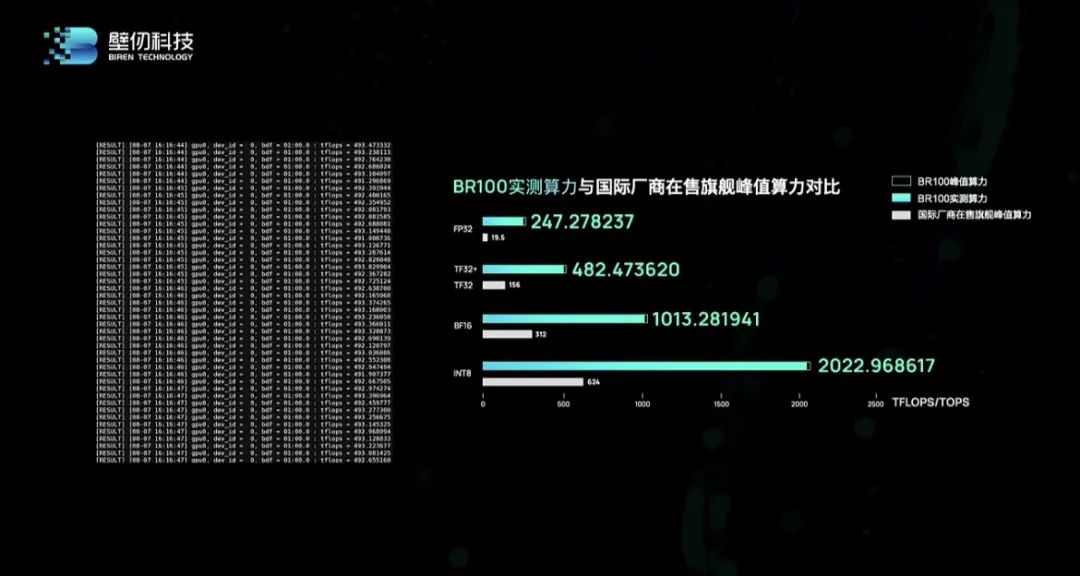
“今年三月底,还处于上海疫情风控期间,壁仞BR100系列芯片率先回片,通过团队的努力成功完成一次性点亮工作。”李新荣透露道,经过4个多月的开发,BR100系列在硬件与软件方面都取得进展,不仅芯片顺利完成工程样品的开发,与服务器设备的适配也有了阶段性的成果,整体系统已在最短时间内进入了产品化阶段,并获得了稳定优异的性能数据。
“作为一家国内初创企业,第一次在极短的时间内完成这样的工作是非常难得的,足以证明我们在前期的设计工作是扎实的、可靠的、经得住考验的。”他感慨道。据徐凌杰分享,壁仞科技已与互联网、云计算、金融、通信、数据中心的行业的头部客户签署战略协议,其中与重点客户已启动产品适配,并进入测试阶段,获得客户积极的反馈。目前BR100应用的重点领域以互联网、通信运营商、行业AI等领域为主。现场,壁仞和浪潮共同发布为数据中心云端训练打造的“海玄”OAM服务器及集群方案。“海玄”OAM服务器可实现8PFLOPS浮点算力,最大功耗7KW。徐凌杰说,“海玄”OAM服务器创全球单台GPU服务器的算力纪录,将于2022年第四季度开放邀测。

基于海玄OAM服务器,壁仞向市场提供一整套具有高性能、高性价比的集群式算力基础设施解决方案。与国际厂商数据中心方案相比,壁仞的数据中心集群方案仅用1/3的服务器数量,实现了更高的浮点算力、更低的峰值能耗和占地空间,同时将标准煤发电量降低64%,具有高能效利用率、实用性、经济性、环境协调性等特性。
壁仞科技还宣布加入百度飞桨硬件生态共创计划,BR100产品与百度飞桨已经完成I级兼容性测试,达到兼容性要求。此外,为了更好服务全球开发者,壁仞科技开发者云已经上线。
04.AI芯片进入拼落地时段
在李新荣看来,高质量人才团队、前沿的产品定位、微架构创新能力、软硬件的高效实现和交付能力等能力,构成了壁仞科技的护城河。“壁仞提供的GPU芯片,不仅仅是解决国产芯片「有和无」的问题,更是解决性能「好和优」的问题。BR100是一种面向客户需求的具备超强算力的通用国产化产品方案,竞争力遥遥领先国内同行。”徐凌杰说。就认知而言,他认为,壁仞团队非常清楚只有追求更高的性能、更低的TCO才能获得商业落地的优势,最重要的是产品竞争力要获得商业客户的认可,才能最终做大做强。据徐凌杰观察,近两年,AI芯片、GPU芯片行业已经过了单纯讲述PPT的时段,更多的是考验企业在具体场景落地等方面的实践。资本市场也更加关注芯片公司在客户侧的实际应用落地反馈。在他看来,当前AI芯片的比拼,关键在于打造有差异性的产品,深入了解客户需求与应用场景痛点,为客户解决业务实际问题,以创新的架构、突破的性能为目标打造产品,而不仅仅是对标已有产品,长期处于追赶状态。“GPU芯片作为大国重器,是目前集成电路领域需要重点突破的关键环节,需要政府、企业、高校长期在技术、人才、资金等方面进行投入。”看向未来,他判断国内通用GPU产业往后发展,最好的结果是能产生1-2家芯片企业,真正赶超国际巨头在加速计算芯片领域的市场地位;最差的结果是需要更长时间去建立国产芯片的技术壁垒,尤其在集成电路全球产业链持续分裂的趋势下,这需要政府和国家投入更多的资源。
05.结语:用系统性思维解决通用GPU落地难题
在通往大规模商用落地的路上,国产通用GPU还有多道难关待闯。李新荣举例说,这包括软件栈的成熟度、客户基础设施的兼容性、产品的性价比、支持的应用种类等都需持续优化。目前,通用GPU面临的一大关键技术瓶颈是提升能效比,现存计算体系架构依然存在内存墙、功耗墙等问题,计算资源规模很难在现有工艺技术下继续实现快速翻倍。这要求GPU企业需要以系统性的思维去解决问题,包括封装工艺、稀疏化、精度类型、光互连、近存储计算等。为了应对这些挑战,李新荣说:“壁仞未来会继续大力布局数据中心的计算产品,持续优化软硬件,不断扩展壁仞在智能计算领域的能力和行业触角,推动产品落地和后续迭代。”

GTIC 2022演讲预告
8月26日-27日,「GTIC 2022全球AI芯片峰会」将在深圳开启。大会以“不负芯光 智算未来”为主题,将于深圳湾万丽酒店大宴会厅举行。
在大会首日上午举行的AI芯片高峰论坛上,壁仞科技联合创始人&CTO洪洲将发表主题为《大算力通用GPU赋能超大模型训练》的演讲,分享下一代具有强大算力的通用GPU将如何支持万亿参数级别的超大模型训练,以高性能、高能效比、高通用性助力人工智能赋能百业。
*博客内容为网友个人发布,仅代表博主个人观点,如有侵权请联系工作人员删除。


